Be yourself; Everyone else is already taken.
— Oscar Wilde.
This is the first post on my new blog. I’m just getting this new blog going, so stay tuned for more. Subscribe below to get notified when I post new updates.
Be yourself; Everyone else is already taken.
— Oscar Wilde.
This is the first post on my new blog. I’m just getting this new blog going, so stay tuned for more. Subscribe below to get notified when I post new updates.
So the simplest database just has a key value pair, The key can be 42 as the userid and the value can be json{“rickson”,”32″,”Philippines”} with API get and set as mentioned in DDIA. It works and is fast because it write append only to a file. The problem begins on reading because the most updated key value could be at the end of the file as same keys are not updated but only write.append only. So you need to scan the entire file for get requests, that’s O(n) which increases when the log size increases.
The improvement over this is to add a hash map in memory with the key 42 and the offset byte in the log. This way searching for 42 userid can directly go to the offset and doesn’t need to scan the entire file. The challenge here is that you can run out of disk space with log. Further improvement can be that the file is itself broken down into segments. A segment has limited size and is closed at limit and a new segment opened. . A background thread could look for duplicates keys and compact them throwing away old values and thus putting the compacted segment into a new segment. Older segments are not modified. Thus each segment can have its own in memory hash map. This is also because you don’t want a global hashamap to keep changing every time there is a segment compaction. if a segment is rarely accessed, it’s hashmp may not even remain in memory. If such a key is requested, bitiask may fall back to doing O(n) search on disk starting from newer segments to older segments. The other challenge with hashmap in memory is range queries. The database engine would just look for each key in the range sequentially.
With SST, we overcome the limitations of having all the keys in memory. How? We dont just append entries, we append them in a sorted way. Even when compaction is done, we create a new segment by taking the lowest key in sort order (handprinted, handlebar) will go into a new segment as (handbag, handcuff, handprinted). Now even if you have some keys like handbag in-memory, and the search request is for handcuff, you know that you can jump to handbag and search sequentially for it. So you still need indexes in memory but sparse, one key for each kilobyte. This also helps range queries because sorted ranges can now be grouped into a block.
But how do you append to a disk file in a sorted manner? That’s where data structures like B-Tree come into place. So if you are asked why use B-tree or it’s variant(B+-Tree), now you know the answer.
Continuing, what is the nice thing about SST? It is that every new write to database can first be strored in-memory in an already balanced tree. Once the meltable is big enough it is stored as a new SST file to disk. This becomes the most recent segment. So when an index key is not found in memory, the engine can fist look into the most recent segment and work backwards. Of course compaction will happen in the background and if there are duplicates found in the most recent segment and older segments a new segment will be created having the most recent value and also sorted.
The only disadvantage of this approach is that a crash in the DB can make you lose the in memory SST BTree orredblack sorted data. The way out is to keep a separate log even for the memtable in memory. But of course this log is not sorted but simply append only to reconstruct the memtable in case of a crash. Elastic Search Lucene etc work on this technology where keys for words are saved as index. SST with logs become LSM log structured Merge trees.
Btress also manage key value pairs for look up. But that’s where the similarity ends. Btrees do not store data in sequential segments. Rather each block of data is like a 4KB page. Each page(node) is an addressable and read of write one page at a time. Pages refer to one another like pointers but in disk instead of memory. One page is designated as a root and you start the search here. Keep moving to its children until you find the key you are looking for. Btrees are sorted so they follow the same idea of SST. the only difference is that optimizing a Btree to be balanced makes the searching, insertion etc efficient. Being balanced is an inherent feature of a BTree. This ensures OLog(n) search, insertion, deletio. Most databases fit into a Btree. So you don’t need to jump too many pages in order to find the page you are looking for. A 4KB page with a branching factory of 500 (no. of child references a nodes can have. Binary tree just has 2 children so branching factor is 2) can fit 256 TB of data. Hence a BTree is ideal for disk storage. It’s not great for in-memory. We can probably use binary tree or similar structures with lesser branching factor for in-memory storage.
Searching in BTree is faster than LSM because LSM has the limitation of sequential segment search when the key is not present. Also LSM writing is fast because it is append only. The compaction etc is the overhead. Btree writing is overwriting the page.
On the other hand to make BTree writes reliable, it needs to make two writes. This is because updates page splitting when a page is full so that two new pages are created and the parent node is also updated – to make all of this reliable, Btree uses a write ahead log. This is an append only log which is written before any update or write operation is done. If something goes wrong or the database crashes the Btree structure can be reconstructed using this log. Also Brees use lightweight latching when concurrent threads try to update the Btree. LSM is actually simpler because their compaction does not involve locks, they do the merging in the background without interfering with incoming requests.
Write amplification – the number of times blocks are written over the course of the lifetime of a database – is another concern which is of particular concern on SSDs. LSMs seems to have lower write amplification, they have better fragmentation because sequential writes means you can clean up during compaction whereas in Btree, you have random writes to a page and if pages don’t fit you, you make new ones so some unused space in the page remains.
But in LSM due to compaction some reads may have to wait till an expensive compaction is done. Also if compaction can’t keep up, you may run out disk due to unmerged segments and incoming reads will have to go through all segments too.
Btree are attractive because unlike LSM that have multiple keys in many segments, the keys are always in one place: in a single page. This makes Btree attractive for transactional approaches. So in many implementations transaction on a range of keys is done by placing the locks directly on the tree.
no one talks about this but the main problem with breaking your apps is code duplication. How do you handle one query (or service that wraps this and/or multiple queries) written natively (or otherwise) that is needed in 2 microservices?
Moving all the (say) Java logic to another service while sharing the same database is not the solution because this makes both services brittle to changes in schema structure
Connections are files in linux so if you don’t close connections those files are still open. Each connection is assigned a random port on your machine. If the connection is left open, that port is “already in use” and can’t be reused.
Close your connections to release resources.
this means your container can take advantage of 4 cpu cores (threads)
lazy loading will make you prone to lazy initialization exception
@Service
public class ParentService {
@Autowired
private ParentRepository parentRepository;
public List<Child> getChildren(Long parentId) {
Parent parent = parentRepository.findById(parentId).orElseThrow();
// Hibernate session is closed here!
return parent.getChildren(); // 💥 LazyInitializationException happens here
}
}Hibernate session is already closed on findById
To avoid this add an @Transaction above the method. Some people add this annotation above the class. The down side of adding this annotion – in general – is that if you call an API or doing some businesss logic, it will not close your connections. The annotation works best for CRUD style service layers where you only pick data.
Starting a thread inside the Spring transaction is considered to be outside and will also throw a lazy initialization exception on access of a lazyily loaded object.
JPA hibernate became popular because instead of finding out what updates were done to a data model and writing update queries, it automatically tracks all the updates and generates the queries itself.
@Service
public class ParentService {
@Autowired
private ParentRepository parentRepository;
@Transactional // Default is read-write
public void updateParent(Long id) {
Parent parent = parentRepository.findById(id).orElseThrow();
// ✅ Change entity state, but never call save()
parent.setName("New Name");
// No explicit save() here!
}
}
Hibernate will automatically flush this to dabase even though no update or save was called. That’s why readOnly=true i.e to define the transaction boundary is important.
$ docker ps
# copy the keycloak container id
# ssh into keycloak container
$ docker exec -it <container-id> bash
# export the realm configuration along with users info
$ /opt/keycloak/bin/kc.sh export --dir /opt/keycloak/data/import --realm sivalabs --users realm_file
# exit from the container
$ exit
# copy the exported realm configuration to local machine
$ docker cp <container-id>:/opt/keycloak/data/import/sivalabs-realm.json ~/Downloads/sivalabs-realm.jsonThis is from siva’s blog
This ngrx blog on side effects got me introduced to the principles of functional programming in java script. I am also reading redux and react. Some principles.
Avoid using global variables or fetching data directly from a component. The redux store is immutable thus you are alway being assured of getting data that has not been mutated.
Some great ideas on cookie and web storage securing here
cookies need http only and secure flag because they were insecure by default. So this was a patch so that no request for https can be sent from http (origin) and no request from a different domain can be sent with a cookie of your server(same-origin). Web storage used over https is http only and secure by default. The challenge in web storage is that they won’t work with sub domains.
http only is useless agains XSS because no attacker – who gets your session token(session hijack) will wait to gain your token and then use it when you could easily log out. What is more possible in XSS is a malicious form being injected by some third party library CDN that you use and such a library adds a POST fetch request that posts to your server because the cookie is anyway present in your browser that is sent along with this request ( in this script). http only does nothing to sort this XSS attack (cross site scripting). It only ensures that document.cookie cannot be used on your site I,e a hijacker cannot use a malicious script to read your cookie so that he can then send it to a remote server and use it. But he doesn’t need to do that as already explained because there are other ways of doing XSS attacks,
of course httponly will help prevent a sub domain that has untrusted scripts because lets say, user-uploaded documents are served on that domain and they can have untrusted scripts injected in those attachments. in this case, if the script from the sub domain were to want to read the cookie of the parent domain, it would not be possible because document, cookie does not work when httpOnly is set
CSRF tokens are tokens that are sent from the server embedded inside every form. Why is this done? Because in the last para we discussed how css attacks can be done even if httpOnly is set by merely having a form submit script from a malicious website injected into your code. When. this form is accidentally submitted, as it has your cookie, it gets accepted by the server. However if the server were to send a unique CSRF token that it stores along with the user session into every form, this token would not be available in the form script that the malicious site has injected. Even if the malicious site generates an “acceptable” token, this “acceptable” token is not part of the user session on the server side. this is how CSRF token is supposed to protect against XSS attacks,
however there is an attack called as double submit CSRF
To protect against CSRF, let the API send back a unique csrf in the response. This csrf token can then be based in the header of each API. Now the attackers malicious form will not have this header value because he’s not aware of the header key nor value, he was only expecting that a cookie would automatically authenticate him. He wasn’t expecting to do the extra leg work of adding a header with the malicious form submit.
This is still the best pattern to create threads.

The executor returns a future. The futures are not blocking but if you want to access the code inside the future, it blocks.
Why is it the best pattern? Because threads are expensive to create. We shouldn’t create a thread by hand (calling Runnable).
The nice thing about callable is that it can return any type and you can throw exceptions inside it. You couldn’t throw exceptions inside Runnable.

An interesting thing to note is that if you’re doing some heavy computation, you shouldn’t have more threads than the core because then the cpu wastes time in scheduling the threads as only one core can run one thread. However, this is different in case of HTTP requests.
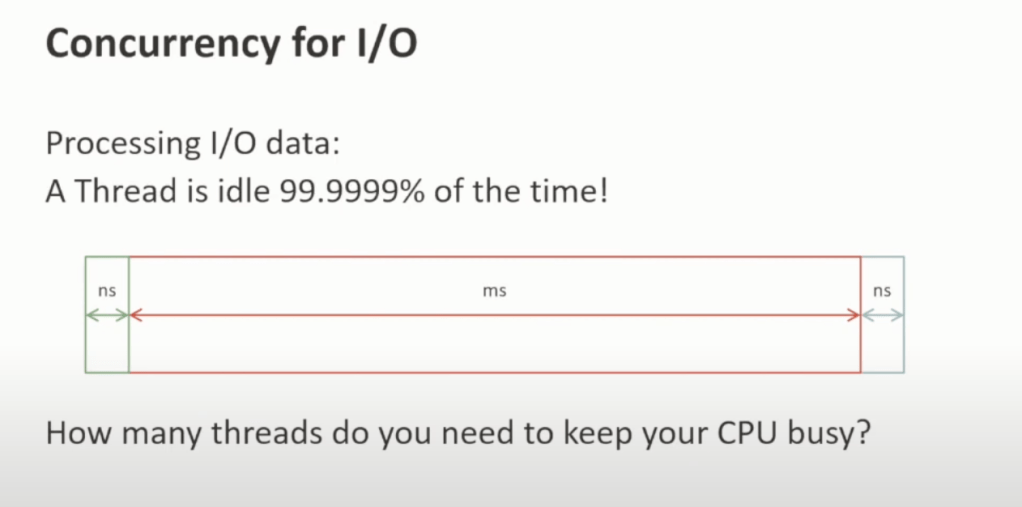
how expensive are threads?

I was watching this video of how an Actor system can be implemented purely in Java without any external library.
Sometimes you watch things because they are interesting but you don’t know where they really fit in your learning curve or your tech-stack. Where will I use this?
Luckily, I read a few more articles that gave me perspective on where actor system fits best. Actor system is essentially part of paradigms in reactive Java where corcurrency is most important due to hundreds if not thousands of concurrent requests and using threads and sharing state between threads could become a bottle neck.
I don;’t want to deep dive on actor system because there are many tutorials out there. I would only like to share insights I gained. What is it that makes actor system fast?
It is the message passing. It is that each thread can use their own state and does not have to share that state with others. It is that each actor, behaviour and effect can be de coupled each having its own state and merely passing messages to the next.
It’s a kind of a mail box patterns there the mailbox of the actor is inside its own object state and hence isolated.
I Was wondering why this article said a blocking queue can be used when I had understood the actor system to be non-blocking.
With Java 19 virtual threads, parking a virtual thread is easy as it is not a system thread, thus even blocking queues can be used. In such an implementation the actor thread can simply be parked or waiting until there is a new message. It doesn’t need to poll.
Akka and many other implementations however simply use a concurrent unbounded queue. This works on the principle of polling. Some concept of atomic operation (CAS) makes this polling thread safe but there is no inherent blocking or synchronization (it is lock free, it uses a different algorithm)
colleague updates lots of file to master. Didn’t realize it. Got a WAR cannot be extracted.
Thought my build broke because I had installed 7zip to make my WAR copy faster and re-built GULP so thought that my WAR was not being able to parse.
Only to realize that Docker caches bindings – paths to columns etc. So when my friend changed some project structures, you had to delete those bindings. Spent a good deal of time trying to figure this out.
docker build –no-cache -t your-image-name .
It amazes me that the most important metrics (lines of code, story points, cycle time, devex satisfaction) in development are the two that are never discussed, let alone measured … mean time to answer (mttA) and mean time to question (mttQ).
A factory pattern with Spring in which there is no if-else loop for creating low-level module objects that are required for the polymorphic dispatch.
Cleaner because there is no if-else loop.
#springmagic
https://dev.to/honatas/factory-pattern-with-polymorphism-on-spring-47e
@Component
public class Dog implements Animal {
@Override
public AnimalType getType() {
return AnimalType.DOG;
}
@Override
public String makeNoise() {
return "Bark!";
}
}
@Component
public class AnimalFactory {
private EnumMap<AnimalType, Animal> animalsMap;
@Autowired
public AnimalFactory(List<Animal> animals) {
this.animalsMap = new EnumMap<>(AnimalType.class);
for (Animal animal: animals) {
this.animalsMap.put(animal.getType(), animal);
}
}
public Animal getAnimal(AnimalType animalType) {
return this.animalsMap.get(animalType);
}
}
A good explanation of the difference between the two phases in the cycle
REST API is great for SaaS products but ever wondered why the Banking world integrating middleware messaging services e.g AMQP? Because already by 2006, Banks were processing 500,000 events per second. Which REST server can make or receive that level of requests?
Was browsing through the comment section of this polemical video.
Found a great comment
But in reality the systems are very different in purpose and use cases. RabbitMQ is an implementation of AMQP, full stop. Just go read John O’Hara’s article “Toward a commodity enterprise middleware”. Being an AMQP, all it does, and nothing else, is delivery of messages to the specified recepient. Again, full stop. As soon as the message is in the memory buffer – it’s done its job. Kafka, on the other hand, is a CDC on steroids. A distributed WAL. There are no messages, therefore, no addressee, there are only “data changes”, which we usually call “events”.
He also shared an article I would like to read
Just reading the amazon dynamo db paper
The amount of mechanisms that are needed in place to make eventual consistency work: vector clocks, conflict resolution of versioned objects, node co-ordinators, replication
only so that you have availability and low latency makes me feel like saying:
please, don’t do this if you are not amazon and your product is never going to reach the level of Amazon. Stay with strong consistency and sleep better at nights.
I have a week’s break. Before the break, I drooled thinking I would be doing Karpathy’s machine learning fundamentals or even MIT distrubuted computing lectures. I have done nothing. Just groceries, some lessons on a testing course and reading 100 years of solitude.
The only things going consistently well is 100 years of solitude. It just goes to show that we could try to dream of being good engineers or build good products on the weekend.
But focus, will and passion isn’t something you can buy over Amazon. This is something that starts early and like jogging or exercise is a discipline.
I had a colleague once do CriteriaQuery something like
empList = session.createCriteria(Employee.class)
.addOrder(Order.desc("id"))
.setFirstResult(0)
.setMaxResults(2)
.list();and then check in an if loop
if(emptiest =! null) {
projectList = session.createCriteria(Project.class)
.addOrder(Order.desc("id"))
.setFirstResult(0) .setMaxResults(2)
.list();
if(projectList != null) {
....
}Apart from not using OneToMany properly and having an endless chain of if-else loops, it seemed he just didn’t want to write an SQL query. He had been bought into the idea that Java can do everything, I needn’t write a query.
All his code could have been reduced to a single model that is more maintainable and cleaner.

No matter how much experience you have in hibernate of JPA, I bet you forget after 2 months if Contacts was suppose to be ManytoOne or User OneToMany and which is the one that lazily loads.
Good luck understanding how to not lazily load while using graphQL
Chapter 1: Why don’t we just use a txt file instead of using a database?
Disk, Flash and RAM speed
Flash drives are about 100 times faster than disk drives but are also significantly more expensive. Typical access times are about 6 ms for disk and 60 μs for flash. However, both of these times are orders of magnitude slower than main memory
(or RAM), which has access times of about 60 ns. That is, RAM is about 1000 times faster than flash and 100,000 times faster than disk.
I have seen code bases where spring authorization and resource servers are present together.
Ideally, organizations have multiple apps and a separate authorization servers. There multiple apps then act like oauth clients or as resource servers. The problem of putting both authorization server and resource server together is that you need to implement the /oauth/token and all the configuration each time when you create a new app.
In fact, you even don’t need an authorization server if you just have a single app. Your resource server can also give out JWT tokens.
@SqsListener("${sqs.book-synchronization-queue}")
public void consumeBookUpdates(BookSynchronization bookSynchronization) {
String isbn = bookSynchronization.isbn();
LOG.info("Incoming book update for isbn '{}'", isbn);
if (isbn.length() != 13) {
LOG.warn("Incoming isbn for book is not 13 characters long, rejecting it");
return;
}
if (bookRepository.findByIsbn(isbn) != null) {
LOG.debug("Book with isbn '{}' is already present, rejecting it", isbn);
return;
}
Book book = openLibraryApiClient.fetchMetadataForBook(isbn);
book = bookRepository.save(book);
LOG.info("Successfully stored new book '{}'", book);
}We want to test if repository returns non null object if logger is printed that book already exists. We write below test
@Test
void shouldNotOverrideWhenBookAlreadyExists() {
BookSynchronization bookSynchronization = new BookSynchronization("1234567891234");
when(mockBookRepository.findByIsbn("1234567891234")).thenReturn(new Book());
cut.consumeBookUpdates(bookSynchronization);
}the reason why we mock and not do an integration testing of actually picking up this value is because mocking doesn’t test if the repository can actually pick up the record. Mocking is done to only test the behavior of the unit i.e to test the logic of this method i.e does it print the log “already exist” when the repository will return non-null?
On the coned repo do
git remote remove origin
Now, add the new repository as the origin for this codebase.
git remote add origin <new-repo-url>
If the branch you want to push to doesn’t exist, create it:
git checkout -b <new-branch-name>
Or, if the branch already exists, just check it out:
git checkout <new-branch-name>
Push the codebase to the new repository on the specific branch.
git push -u origin <new-branch-name>Even if you identify as a mere programmer, at some point you may come across need to share your localhost data across the wire: ngrok.
Today ngrok did not work on my machine due to DNS issues. Understanding fundamentals that power your ‘programming’ is liberating.
This solved my ngrok issue. My DNS was set to router’s at 192.168.0.1. Setting it to 8.8.8.8 got ngrok to foward request to my local.

In this simple image is summarized the marriage between testing and DI. The idea of mocking and doing test assume that if your dependcyies change e.g tomorrow if you’re fetching books metadata not from open openAPI but from some other library, then you can change the dependency but the tests written for findByISBN can also be mocked with the new vendor objects but the basic code above doesn’t need to be changed.
IntelliJ can create a spring test class.
You can create a Parameterized Test that picks up test data from a csv
You can create JunitExtension classes that randomly test from a dataset
You can display a pleasant name for the test failure using @DisplayName
You can hint what failed next to assertFalse(result, “Did not detect bad email”)
Test can be parallelized by configuring surefire-plugin – plugin that runs unit tests in maven – to run parallelly/ concurrently
If you have npm resources being built as part mvn test they can be skipped using
mvn test -Dskip.npm
When you press play button to run tests in IntelliJ, it the same as doing mvn test
Instead of @InjectMock you could simply instantiate the object in BeforeEach block.
If you try to test say verify(bookRepository.save, count(1)) and this code is not present in the service class, mockito will complain in default strict mode.
You can test to check if an exception is thrown.
when(mockOpenLibraryApiClient.fetchMetadataForBook(VALID_ISBN)).thenThrow(new RuntimeException("network timeout"));
cut.consumeBookUpdates(bookSynchronization);
Assertions.assertThrows(RuntimeException.class, ()-> cut.consumeBookUpdates(bookSynchronization));
If an exception is eaten inside the class, your test will fail.
Repository test can be done to check if entity manager, datasource and repository are not null. But this is trivial. Service objects will not be injected in repository tests.
@DataJpaTest(properties = {
"spring.flyway.enabled=false",
"spring.jpa.hibernate.ddl-auto=create-drop"
}) this should not be used in production but is handy for debugging on staging and local
The reason this is being done is because if you have configured your flyways scripts to postgresql, and @DataJPATest uses in-memory H2, you are going to have issues. So you can disable flyway and let the tables are recreated On h2.
There are many styles of writing code.
Early exit – Advantage of doing this is that after skipping “the early exceptions, you know that the rest of the code is business logic and has fewer validation loops.
if (! reviewVerifier.doesMeetQualityStandards(bookReviewRequest.getReviewContent())) {
throw new BadReviewQualityException("Not meeting standards"
}
Review review = new Review();
review.setBook(book);
review.setContent(bookReviewRequest.getReviewContent());
review.setTitle(bookReviewRequest.getReviewTitle());
review.setRating(bookReviewRequest.getRating());
review.setUser(userService.getOrCreateUser(userName, email));
review.setCreatedAt(LocalDateTime.now());
review = reviewRepository.save(review);
return review.getId();
Late exit by else loop
if (reviewVerifier.doesMeetQualityStandards(bookReviewRequest.getReviewContent())) {
Review review = new Review();
review.setBook(book);
review.setContent(bookReviewRequest.getReviewContent());
review.setTitle(bookReviewRequest.getReviewTitle());
review.setRating(bookReviewRequest.getRating());
review.setUser(userService.getOrCreateUser(userName, email));
review.setCreatedAt(LocalDateTime.now());
review = reviewRepository.save(review);
return review.getId();
} else {
throw new BadReviewQualityException("Not meeting standards");
}
Exit only if exception are thrown. In this style, the validateQualityStandards will throw an exception. You rely on “handling” those exceptions.
try {
validateQualityStandards(bookReviewRequest.getReviewContent())
Review review = new Review();
review.setBook(book);
review.setContent(bookReviewRequest.getReviewContent());
review.setTitle(bookReviewRequest.getReviewTitle());
review.setRating(bookReviewRequest.getRating());
review.setUser(userService.getOrCreateUser(userName, email));
review.setCreatedAt(LocalDateTime.now());
review = reviewRepository.save(review);
return review.getId();
} catch(Exception e) {
throw new BadReviewQualityException("Not meeting standards");
}code samples are from Philip Rieck testing master class. It’s a great resource to learn spring boot testing, please take a look at his course here and options for buying the course are here.
In a recent project, I really understood how to interplay 200 and 201. Until now, some of our API were just returning 200 when a POST API is successful. Why should I return 201, I can just return 200 to say that the API was successful which means the /createemployee API did what its supposed to do, isn’t it?
I spend time on HAPI-FHIR GitHub project recently. Here, an interesting thing happens. If you do a POST for /Patient it will create a patient and return 201. In case you do a POST again and the same Patient exists, it will create a copy of that Patient and return 201 again.
However, you could also use the same /Patient API and do a “conditional create” passing some flag. The conditional create first checks if a patient with that id exists. If it does, it returns the entire object in its response and returns a status of 200.
This should now tell you that The API did not create any new patient and that a patient already exists and Patient that exists has this data inside the DB which has been provided in the response.
Something so simple was fascinating me me. Why? No need of throwing unnecessary exceptions if the record already exists, no need of fumbling the response, 200 says the API was ok but 201 says a new employee was really created. Beautiful!

Library code is beautiful to debug. 30 lines of code packed with hundreds of different combination of classes and configuration.
Any good code would serve multiple purposes.
But if I were to write like this in my org, to make something generic: I would be asked tons of Qs: Why did you put while loop inside of else, why more than 2 if loops etc, why did you not break down this function further, why doesn’t it return a value?
Presently working with pure java package FHIR that has its own restful server and serializer. It is integrated into SpringBoot to leverage JPA. Boot’s deserializer cannot natively convert request to model.
Spring allows you to override boot’s serializer for classes of FHIR.
People call Java/Spring Boot over engineering.
Do other ecosystem also provide such a clean way of extending capabilities, overriding serializers for specific cases?
Interested in learning outside my bubble.
In a next-react course this is how I added my db url
DATABASE_URL="postgresql://dbserver@localhost:5432/username:password"
DATABASE_URL="postgresql://dbserver@localhost:5432/username"second url is incase there is no password.
In java yml though it would be enough to mention localhost.
datasource:
url: 'jdbc:postgresql://localhost:5432/hapi'
where hapi is the name of the database inside the database server localhost.
For all its fancy security @ preauthorize annnotations/ yaml/propertiers config, what pisses me off is there is no simple way to leave all the annotations , filter chains etc as they are and just disable the whole thing with a flag just as it exists for other libraries e.g flyway
Whether IntelliJ or otherwise, you can add GC logs by adding the following VM Opts
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:file.log
I have observed how retry via background processed are done in the industry in code bases.
A scheduler task can pick up data to process and if it finds say 100 records to retry, it will now have to apply a for loop to process those hundred records.
The for loop style of processing seems complicated to me. The reason is because, first the 99 retry objects are in memory and will be processed only after the first one is completed.
second, the job thread itself is blocked because instead of processing one record, the query picked up all failed records and now the worker thread can only be free when all 99 records are processed
third, if there is some exception when retrying the first thread, I now have to eat exceptions and write code in such a way as to have to train other developers to understand that as the for loop needs to run, I have to eat some exceptions so that the next retry object can be processed even though the first one has failed.
This style now can get further complicated. imagine if you find that the first record has failed because of some systemic issue. You know that the rest 99 also will fail due to the same reason. Should you continue the loop or write custom exception that is not eaten if the code encounters some systemic internal error as opposed to (say) a http error or query error for the first retry record which may not occur for the 2nd retry as it may use a different query.
All this makes me feel like the job worker thread is being made to become part of the businesss background thread.
In summary, I would like to see examples of code written in a more decoupled way so that for loops are avoided or worker threads are freed sooner.
Event comes in
model of event
the idea of the event is to save it, process it save its status
Event has many subscribers. Lets call them external subscribers. There are two clients.
A client may want the event data to be passed to multiple web hooks.
So now we have to clone those events so that each event status can be properly mapped to both external client.
What is more, if one external client has two web hooks, that makes 3 change events: 1 for the first ext. client and two more for the second who has two web hooks.
Now, 3 event will have to be processed. But the first event is already “in process”.
Problems
you will see code like this
Response res = eventServicer.processDataForWebhook(event);
if (res == null || res.data().isEmpty()) {
saveFailedStatus(event, StatusEnum.FAILED);
continue;
}Why is there a continue in the loop? May be other places in the code will have a “return;” and not a continue. So when should the control return and when should it continue to the next event?
This makes the developer have to read all your code and always keep in mind that the events are running in a loop and that he should try not to tread on a land mine that makes the for loop break lest other events are not processed. Or is it ok if the loop breaks?
To me, this is one of the challenges in processing events in a loop.
How I would have done it different
Step 1: Event Store
In step 1, events from Message queue received are merely stored into EventStore
Step 2: PreProcessingChangeEvent Store – A task will read from EventStore periodically
At step 2, all events from EventStore are collected and clones are created for 2 criteria
i. An event can have two external subscriptions so event e becomes e1 and e2 with e1 having clientid ABC and e2 having clients XYZ
ii. An event’s external subscription – say, client ABC may want his data at multiple endpoints – e.g http://abc.com/receivedataforanalytics & http://abc.com/liveddatafordashboard. This would mean we now need 3 clones of the original event, e1.1, e1.2 and e2. All have the same data in the event except e1 & e2 have different clientid and e1.1 &e1.2 though have same clientid have different destination endpoint url. So now we can track the status of web hook subscription independently. (status e.g did sending the notification(or entire data) to url of e2 fail? Did processing of data for e1 fail even before sending? how many tries to retry for client ABC? etc
Now that we have 3 events, we can now store them in ChangeEvent collection(table).
Step 3: A task will read events from ChangeEvent and process them at
processChangeEvent()
This decoupling avoids for loops , blocking code and convoluted error handling.
Step 4 A task for processing failed events: Retrying logic should not be different for processChangeEvent() Otherwise, we end up duplicating code. the task should periodically run, pick up failed events and redirect them to processChangeEvent()
Complex web applications would be virtually impossible to write if you had to worry about explicitly passing class instances to all constructors
https://x.com/PkiMike/status/1830660407293575318?t=KzLfpEMBlZbRnKDZ1xVk6g&s=19
after Paul Graham wrote founder mode at https://paulgraham.com/foundermode.html?s=09
sriram subramaniam wrote at https://x.com/sriramsubram/status/1831006974454177869?t=jEW1RPKU5gnu43jRGS834A&s=19
My 2c on PG’s founder mode. I joined Confluent when it was around 20 people. I became a manager and grew to be a VP there (a role that is getting much flak right now!). I am now a founder of a company. I believe founder mode is a persona and does not have to be just the founder who is the CEO. It is critical to achieve founder mode at all levels in a fast-growing company.
First, the concept of founder mode needs to be more clearly defined. This can be challenging because it stems partially from inner feelings that are difficult to articulate. My best attempt at explaining it would be that a person in founder mode embodies two key things-
I like to believe that I had both of these traits when I was at Confluent. The only thing that I wanted was Confluent to succeed. I did whatever it took to make it happen and often was down in the weeds, solving some problems even when I had a large organization to manage. I got myself involved in issues outside my organization, including product and GTM, if I cared deeply about it. It did create friction with others since most are used to a typical corporate system with well-defined boundaries and roles. I also had a lot of context and insights that helped me make decisions or pitch strongly to the founder on what we can do.
Hiring leaders with this mindset is extremely hard. You have to be lucky to find them, and if you do, retain them at all costs. They are fewer than the typical executives who care about personal growth and success or execute the standard playbook. Founder mode has no playbook!
A successful company needs founder mode at all levels. This is how a company can succeed. Recursively achieve founder mode. This helps scale the organization with the same founder intensity at all levels. This is the only way. Hire people who have the founder mindset!
My first into machine learning was trying to do voice to text so I thought let me start with Java even though Python is the most popular in fact it’s the lingua franca of machine learning so anyways I start with just to see what the tooling and ecosystem of machine learning on Java can be like so I looked up Claude and Claude help me pretty good it’s just that I complicated the project by trying to add both – transcribe & summary. The latter part was to learn how LLM’s work.
In this blog piece first focus on the part just to tell you what I learned . I downloaded a library called Java deep Java library DJL. I learned that this library is made by Amazon.
I download hugging faces as the model for machine learning. On the hugging faces website there were files with .py format. The app wouldn’t run complaining that .pt file is missing. I had Pytorch Library set up in POM. I believed PyTorch library would in Java would talk to these models. I could I couldn’t understand what was wrong.
At some point I realized that DJL interfaces with the PyTorch engine but the PyTorch engine in java library is looking for a .pt file. I started renaming my .py file into .PT. With a bit of more digging, I found out that Java uses torch script compiler under the hood and makes C++ calls. This meant, I will have to convert my py torch model to torch script
The other model I stumbled onto while reading up on NLP is the NER model which is the models for doing name location and organization learning. If you have a piece of text this model tell you an organization has been referred to or if a location has been referred or a name has been referred.
What could be the case for this? If someone is involved with web scraping somebody could create a model that identifies if a bran name “apple” was cited. Now you could say, we could merely use an “if loop” to check if there is a word == “apple”. The latter would not tell you if the text is talking about apple as a fruit or apple as the city Big Apple or Apple as a big company. The former, NER model would do that for you because it is trained to understand the the semantic context of a text and the word apple.
<root level="ERROR">
<appender-ref ref="RollingFile" />
<appender-ref ref="Console" />
</root>
<logger name="com.example" additivity="false">
<level value="${LEVEL}" />
<appender-ref ref="RollingFile" />
<appender-ref ref="Console" />
</logger>
<!-- Logger for Spark -->
<logger name="com.zaxxer.hikari" level="TRACE" additivity="false">
<appender-ref ref="RollingFile" />
<appender-ref ref="Console" />
</logger>
<logger name="org.hibernate.SQL" level="TRACE" additivity="false">
<appender-ref ref="RollingFile" />
<appender-ref ref="Console" />
</logger>
<logger name="org.hibernate.resource.jdbc" level="TRACE" additivity="false">
<appender-ref ref="RollingFile" />
<appender-ref ref="Console" />
</logger>
<logger name="org.hibernate.engine.transaction" level="TRACE" additivity="false" />
<logger name="org.hibernate.engine.transaction.internal.TransactionImpl" level="TRACE" additivity="false" />
<logger name="org.hibernate.resource.jdbc" level="TRACE" additivity="false" />
<logger name="org.hibernate.internal.SessionImpl" level="TRACE" additivity="false" />
<logger name="org.hibernate.jpa.internal.EntityManagerImpl" level="TRACE" additivity="false" />
<logger name="org.springframework.orm.jpa.EntityManagerFactoryUtils" level="TRACE" additivity="false"/>
<logger name="org.springframework.orm.jpa.SharedEntityManagerCreator" level="TRACE" additivity="false"/>
<logger name="org.springframework.transaction.interceptor.TransactionInterceptor" level="TRACE" additivity="false"/>
<logger name="org.hibernate.engine.transaction.spi.AbstractTransactionImpl" level="TRACE" additivity="false"/>
<!-- Spring JPA and Transaction Management -->
<logger name="org.springframework.orm.jpa" level="TRACE" additivity="false" />
<logger name="org.springframework.transaction" level="TRACE" additivity="false" />
With above logs, I was able to see traces of logical connection being opened and closed by entity manager. The trick is to put it on tract and to keep the root level at ERROR. Ideally with root level ERROR, it should not show any logs with lower precendence. But due to additivity=false being added to all the individual traces, they are not pushed up to root and traces will show up.
jdbc:${DATABASE_URL:mysql://usr:User12345@localhost:3307/employeemanagementdb}The advantage of doing this is the .env file is supplied by docker or elastic bean stack of was secret server. And your application can pick up the same without having your server urls etc be hardcoded into the sub versioning system
Finding so many implementations of a binary tree, it occurred to me why then do databases use a Btree? Here’s a good explanation.
TLDR; Btrees have many children. Why have a single element in a node when a node can contain many children? What is more, data is read as blocks anyways, so if you can pack in more children into a block, the more the merrier. This read-block structure and multiple children allows Btree to have smaller depths (a depth of 4 with 500 children of each child on a page of 4 kb can hold 256TB of data!). Smaller depths mean lesser accessed as each jump from a node to its child means a new disk read. Hence Btrees are optimized for larger size (blocks)database file systems that don’t fit into memory and binary tree perhaps is optimized for smaller size that fit into memory.
Here’s the writeup for adapter. And here is a good example of it. One way of doing adapter is similar to a facade where you avoid directly referencing third party dependencies.
The canonical example is the InputStreamReader. This class acts as an adapter.

InputStream is an abstract class in Java that represents an input stream of bytes. It is used for reading raw byte data from various sources, such as files, network connections, or byte arrays. The key methods include:
int read(): Reads the next byte of data.int read(byte[] b): Reads a number of bytes into an array.Reader is an abstract class that represents an input stream of characters. It is designed for reading character data, which is essential for text processing. Key methods include:
int read(): Reads a single character.int read(char[] cbuf): Reads a number of characters into an array.InputStreamReader is a concrete implementation of the Reader class that adapts an InputStream to a Reader. It allows you to read bytes from an InputStream and convert them into characters, making it easier to handle text data.
By Accepting an input stream and converting it internally into a Reader( StreamDecoder). Now reading from the InputStream can read characters instead of reading bytes.
It seems like going through Haskell improves us in a general way in writing code. I found some books on Haskell and would like to document it. There’s Haskell from the very beginning. Here’s a more fun looking Haskell book
Some really good visualization of Martin Klepmaan classic book on DDIA by Saurav here.
At every level the parent Page will point to 500 different child Pages. It’s safe to say that after 4 levels the number of Pages in a B-Tree will be equivalent to the following number.
Number of Pages = (500)^4 pages
= 5^4 * 10^8 pages
= 625 * 10^8 pages
Since every Page has a size of 4 kilobytes, hence the total data stored by the B-Tree will be equivalent to the following.
Capacity of the B-Tree = (Number of Pages) x (Size of Page)
= 625 * 10^8 * 4 Kilobytes
= 2500 * 10^8 Kilobytes
= 250 * 10^9 Kilobytes
= 250 * 10^6 Megabytes
= 250 * 10^3 Gigabytes
= 250 Terabytes ~ 256 Terabytes
The common misconception with LIMIT is that
select * from SomeTable LIMIT 10; will only return 10 records. Beware!!!
In a table with 10 million rows, this will do a table scan and try to load all 10 million rows into memory and then limit it to 10 records.
Only after SELECT, WHERE CLAUSE, GROUP BY has computed a result-set is a “limit” applied to that set and the final result set returned.
Researching on a vendor, doing a slide deck on offerings and trade-offs, suggesting potential functional architecture and getting in touch with potential vendors to take a call on either going open source or picking something from a shelf.All this is great skill.
It is tempting during information gathering to open a hundred tabs.It is important though to put all this into paper so that not only you but also others can chew on your research.Gradually, you will see your notes turning into a story. And it will lead you to your next step.
Try to keep your notes in an easy place with pictures, title, subtitle, hyperlinks to cite source of your information.
The title serves as the category of your notes and could repeat for several slides. The sub-title is the real context for the title. It explains why the title I,e the category is not done yet.
You could export your slide deck as a pdf and version it. Every time you add some notes, change the version e.g System overview 2.0 If you wish to be more rigorous, you could also mention the changes in each version in glossary.
Another interesting part of painting a document is that you could also add into it disparate but useful information like comments left on Teams or Slack and add it to your ppt so that it is a common repository of all suggestions, comments and feedback on your research.
Supposing your information led you to contact vendors? You could also mention in the deck that ABC vendor was contacted with the following email at the following address and even the replies. This way, there is also progress being tracked in your document.

This is a good visual representation to how many instances of an application are deployed.
“why don’t we just drop requests that have timed out? Why are we serving them at all?
Notion’s sharding strategy is simple and beautiful. But a unique lesson I learned from all of this is below
“As a precaution, the migration and verification logic were implemented by different people. Otherwise, there was a greater chance of someone making the same error in both stages, weakening the premise of verification.”

Quiz.Quizzes throws an error but
INSERT INTO “Quiz”.”Quizzes” works!
PgAdmin4, Why so strict?
At around 2 billion records, your txnID resets to 0 making all older records with higher txnID invisible to the current session. In Postgres stops writes to DB in order to avoid such data anomalies.
How do more people not talk about his?
https://blog.sentry.io/transaction-id-wraparound-in-postgres/
After spending a few day cleaning data from xml files, they are finally ready for ingestion into Redshift. Data is prepared as relational tabes. Ready for inserts using hibernate and jdbc redshift driver.
Results? 2k-4K inserts per minute. Which means I will be able to do my 200K inserts in around 6-8 hours. What gives?
Then go online to AWS docs which says: Prepare the data in csv, zip it, upload to s3 and use copy command on Redshift. Some benchmarks people have got doing this is loading million records in less than 4 minutes r i.e around 20K inserts per second.
Always read the docs first.
A Java thread pool executor with a core size of 5 and max size of 25 is not going to scale to 25 if your queue is large and requests keep getting queued. Only once the queue is full will core size start increasing beyond 5.
What if I make my queue small but my additional requests that come in can’t be served even by 25 threads? Then your additional requests will start being rejected?
What if I am running a for loop and I dont prefer to exit the loop? You could use a RequestRejectionHandler that ThreadPoolTaskExecutor exposes.
Or, use a ThreadPoolTaskExecutor backed by a LinkedBlockingQueue. This queue blocks on the main thread if the queue is full instead of rejecting events.
If you have a class heirarchy that adds more and more parameters to constructors as it goes down the (inheritance) chain, consider using builder pattern.
public class Animal {
private String name;
public Animal(String name) {
this.name = name;
}
}
public class Mammal extends Animal {
private String furColor;
public Mammal(String name, String furColor) {
super(name);
this.furColor = furColor;
}
}Consider using the builder patterns as shown here.
the problem I have with this technique is that: s this example trying to say that no inheritance chain may be required if we could put all the paramters of the chain of classes into into one class and just create a builder with some fields being optional and others throwing exception if missing?
If yes, how do we define behaviors on this object if it has so many fields i.e it’s essentially has data for many behaviors: animal, mammal, dog, cat etc.
Multiple RPC requests to a service will have different latencies, but they often will cluster near similar values for similar requests.

A quick but useful way to describe a long-tail distribution is to give the 99th percentile value, or 95th, 99.9th, etc. The 99th percentile value for the histogram in Figure 1.3 is 696 milliseconds, which is much too large compared to the 50-millisecond goal. It represents a serious performance bug.
2. Where JPA has really triumphed is the difficulty of testing native queries that are concatenated with multiple conditions
e.g if coupon != null
query += “AND coupen =’Valid'”
Adding your own concatenated string to this query makes it hard to test he entire query for all its conditions.
3. Always write tests when starting out
4. Always manually test your code before sending it to your colleague
5. Make sure you note down credentials production keys etc. You are going to forget it.
6. Do not keep code stashed in git for too long. You could lose it if git gets corrupted. It is better to comment and commit, create a separate remote branch or add a feature flag that disabled your code.
7. Using primitives in your API. If someone adds a null, your API doesn’t fail but your business logic is now flaky because a null has got introduced. Was it better for the API to fail than to accept a null? The problem with primitives is that they are often initialized to 0 when a NULL could have been ok.
8. Always abstract your code. If you are starting a jetty server inside a method. Ask yourself if you could have passed a server variable so that any server can be used and it doesn’t have to be Jetty.
fun getToDoList(user: String, listName: String): ToDoList {
val client = JettyClient()
val response = client(Request(Method.GET, "http://localhost:8081/todo/$user/$listName"))
return if (response.status == Status.OK)
parseResponse(response.bodyString())
else
fail(response.toMessage())
}
Traditionally, if your CSV file is present in a folder inside your ec2 instance, something like this is good enought to read the CSV
CSVReader reader = new CSVReader(new FileReader(filePath))After this, you are good an can loop each line
while ((line = reader.readNext()) != null) {
}What if your file is inside resources?
My struggle has been to provide this path to resources folder in spring boot java configuration
if I tried
new ClassPathResource("/eligibility-payerlist.csv").getFile()
CSVReader reader = new CSVReader(new FileReader(file))What worked for me is
InputStream inJson = SomeClass.class.getResourceAsStream("/list.csv");
Reader reader = new InputStreamReader(inJson);
CSVReader reader = new CSVReader(reader )Or put another way, there’s an ultimate tradeoff between capability and trainability: the more you want a system to make “true use” of its computational capabilities, the more it’s going to show computational irreducibility, and the less it’s going to be trainable. And the more it’s fundamentally trainable, the less it’s going to be able to do sophisticated computation.
(For ChatGPT as it currently is, the situation is actually much more extreme, because the neural net used to generate each token of output is a pure “feed-forward” network, without loops, and therefore has no ability to do any kind of computation with nontrivial “control flow”.)

LLM is good at semantic computationally shallow not precise algorithmic precision like paranthesis.
yes, up to a certain length the network does just fine. But then it starts failing. It’s a pretty typical kind of thing to see in a “precise” situation like this with a neural net (or with machine learning in general). Cases that a human “can solve in a glance” the neural net can solve too. But cases that require doing something “more algorithmic” (e.g. explicitly counting parentheses to see if they’re closed) the neural net tends to somehow be “too computationally shallow” to reliably do. (By the way, even the full current ChatGPT has a hard time correctly matching parentheses in long sequences.)
How does LLM know that certain words like black cat can go together and electronic cat doesn’t make sense? This is done by embedding vectors.
how does chatgpt know if a sentence is meaningful?
Inquisitive electrons eat blue theories for fish – is grammatically correct but isn’t something one would normally expect to say, and wouldn’t be considered a success if ChatGPT generated it—because, well, with the normal meanings for the words in it, it’s basically meaningless.
But is there a general way to tell if a sentence is meaningful? There’s no traditional overall theory for that. But it’s something that one can think of ChatGPT as having implicitly “developed a theory for” after being trained with billions of (presumably meaningful) sentences from the web, etc.
How did chatGPT learn the syllogistic logic that is foundation of a meaningful sentence without those rules being added to it like a template?
it’s reasonable to say “All X are Y. This is not Y, so it’s not an X” (as in “All fishes are blue. This is not blue, so it’s not a fish.”). And just as one can somewhat whimsically imagine that Aristotle discovered syllogistic logic by going (“machine-learning-style”) through lots of examples of rhetoric, so too one can imagine that in the training of ChatGPT it will have been able to “discover syllogistic logic” by looking at lots of text on the web, etc.
perhaps there’s nothing to be said about how it can be done beyond “somehow it happens when you have 175 billion neural net weights”.
hopefully one day I will come to appreciate/understand the problem he is trying to address.
source is here
I don’t think people understand just how true this is.
To be fair, and I’m going to be SUPER FREAKING BLUNT HERE. You want to know where the most vulnerabilities are going to be in the next decade?
Kubernetes clusters.
In the race to containerize literally everything, and the false assumption that they somehow improve security (they absolutely do not).
The TLDR is that each container is running with a shared kernel with kernel namespaces. They aren’t isolated by the CPU. If one containerized application takes over the kernel/host, the entire stack is done. So if you built a generalized container solution that’s intended to run disparate applications and application layers, you’re doing it wrong.
But you know what? I guarantee this is being done. Guarantee. And it’s going to be even better because everyone still treats them as VMs. As time goes on, nobody’s going to want to maintain these environments. If you’ve got an application with 500 containers that’s been running for 3 years straight without re-deploys–which one of you lucky folks is going to be the one that has to push the button? Who’s going to do it?
Nobody.
This is a technology that was built by a team at Google. Again, it’s not that Google is bad by any means; but the reality is that software is vulnerable. Windows goes as far as segments even consumer OS’ from critical components into a separate VM. And they’re ever increasing this isolation layer–effectively turning core parts of Windows into Qubes OS with dedicated communications APIs.
Which btw, I’m actually a really big fan of Qubes OS and isolation in general, along with Mandatory Access Control (SELinux/AppArmor/etc)
Sagas pattern was a paper written by some folks in Princeton University in 1987. It was trying to solve the problem of non-scalability of distributed transactions that. In distributed transactions, transaction coordinator is the single point of failure. Due to lock acquire and orchestration it can easily become a bottleneck.
Sagas is eseentially a compensation pattern – we allow individual services to run on their own databases but compensate for failing ones.
Thus sagas is a long lived transaction that is a
“A Saga is a Long Lived Transaction that can be written as a sequence of transactions that can be interleaved.
All transactions in the sequence complete successfully or compensating transactions are ran to amend a partial execution.”
Compensation transactions: If your hotel in the hotel service is already booked but the car rental service couldn’t book you a car and if the saga is aborted, a compensation transaction would be a cancel API to unhook the hotel room. The room would be reserved for a very short amount of time and then would be free for booking for others in case the saga fails and needs to be aborted.
The tradeoff in sagas is atomicity in order to have availability.
Sagas has a SEC coordinator but do not confuse it with the coordinator of 2PC. Because SEC has no state, it can die but the truth of the individual transactions will still remain the log (regardless if the log is Kafka or some other database)
compensating requests are re-tried indefinitely in case sage is aborted. Hence these compensating requests must be idempotent (so that retries achieve the same result).
What if the saga coordinator goes down? There could be multiple saga co-ordinators like Kafka brokers. If one goes down, the other can pick up from the same place as it is sort of clustered. Now I see the reason why Kafka works well as a distributed log. If you want to do a saga abort compensation requests and not lose the coordinator, you need a distributed log.
I learned that the usual java enterprise code is a transaction script which is pull data, dome business code, alter some data, some business code and then prepare response.
This code is hard to test. Fictional Programming puts all business code together.
The dependencies in OO programming can easily make object graph very complex with multiple cyclic dependencies. The object graph in FP all point from left to right. It’s amazing how they do this. Also, FP reflects onion architecture more closely as the pure business code is in the centre the APIs, network, integrations, infrastructure all in the peripheries.
Simple explanation from JLS: “If a final variable holds a reference to an object, then the state of the object may be changed by operations on the object, but the variable will always refer to the same object.
@Repository
public interface StockRepository extends RevisionRepository<Stock, Long, Integer>, JpaRepository<Stock, Long> {
@Query(value = "SELECT stock_akhir.product_id AS productId, stock_akhir.product_code AS productCode, SUM(stock_akhir.qty) as stockAkhir "
+ "FROM book_stock stock_akhir "
+ "where warehouse_code = (:warehouseCode) "
+ "AND product_code IN (:productCodes) "
+ "GROUP BY product_id, product_code, warehouse_id, warehouse_code", nativeQuery = true)
List<Tuple> findStockAkhirPerProductIn(@Param("warehouseCode") String warehouseCode, @Param("productCodes") Set<String> productCode);
public List<StockTotalResponseDto> findStocktotal() {
List<Tuple> stockTotalTuples = stockRepository.findStocktotal();
List<StockTotalResponseDto> stockTotalDto = stockTotalTuples.stream()
.map(t -> new StockTotalResponseDto(
t.get(0, String.class),
t.get(1, String.class),
t.get(2, BigInteger.class)
))
.collect(Collectors.toList());
return stockTotalDto;
}when you look at the other solutions on this page, you will know that the Tuple is taking us back to JDBC result mapper but in this case, is “keeping it simple”
The whole idea of placing repositories private to the package where its service class resided is: business validation.
If you have conditions only when satisfied should someone invoke a repository, making it public for all packages would simply allow any service to invoke this repository and there by skip these validations.
func worker(in <-chan *Work, out chan<- *Work) {
for w := range in {
w.z = w.x * w.y
time.Sleep(time.Duration(w.z) * time.Millisecond) // Simulating work with Sleep
out <- w
}
}The reason why the channel out has a type specified (chan<- *Work) while the channel in does not have a type specified is due to the directionality of the channels in Go. Therefore, the directionality of the channels (chan<- for sending and <-chan for receiving) is specified based on how the channels are intended to be used within the function.
type Work struct {
x, y, z int
}
func main() {
// Send some Work items to the work
work := &Work{x: 2, y: 3}
}if the & operator is not used, the struct will be placed on the stack by default in Go, while using & explicitly places the struct on the heap. Placing the struct on the heap allows for more efficient memory management, especially when working with complex data structures or when you need to pass the struct by reference rather than by value
If you have a function
func worker(in <-chan *Work, out chan<- *Work) {
for w := range in {
w.z = w.x * w.y
Sleep(w.z)
out <- w
}
}that expects a reference but send it
work := Work{x: 2, y: 3} // create a struct Work and assign it to work
instead
work := &Work{x: 2, y: 3} // Create a pointer to WorkGo compiler will complain as Go is statically typed language
Multiple return types
func values() (int, int) {
return 2, 4
}There’s an interesting video here that shows that returning pointers instead of returning values was slower in benchmarks. This is because pointer are stored on heap and heap allocation is done during run time and GC can kick in whereas functions returning value have stack allocation done during compile time.
Structs are saved on stack. What if the struct itself has a pointer reference?
The allocation of the struct itself is still going to have the same overhead. If additional overhead is added because of dependent heap allocation, then that overhead will be the same for both value and pointer. (didn’t understand this point)
If you want to return an address and if the addresss is on a stack. Then, Go could create a copy of address and (say) return it to main (the active frame). The problem here is that the address copied and returned to main points to a value that is destroyed because the stack is destroyed. Hence, addressses are always stored on the heap. When returning an address, Go will copy the value to the heap and return this addresss to the caller(main) and this value can now be accessed as it is on a heap.
Go routines
func main() {
go count("sheep")
count("fish")
}
func count(thing string) {
}when a func is prefixed with “go” it becomes a goroutine. However, the main function itself is also a coroutine.
if both functions are groupings in main, main will just exit and nothing will be printed.
Assignment operator := and =
The difference between = and := in Golang lies in their usage for assignment and declaration. The = operator is used for assignment to already declared variables, while the := operator is used for declaring and initializing new variables.
%s and %v
s is used to format a string value, meaning that the argument will be treated as a string and printed as-is.%v, on the other hand, is used to format a value in its default format, which means that the argument will be printed in the format that is most appropriate for its type.
Why use pointers?
func main() {
a:=4
squareVal(a)
squareAdd(&a)
}
func squareVal(p int) {
fmt.println(&p,p)
}
func squareAdd(p *int) {
*p *=*p
fmt.println(p,*p)
}
when You call squareVal, you are passing a copy of variable a. Every functional call works on its own frame inside a stack so Go can achieve immutability as no one can access the stack of the main function where a resides.
However when you call squareAdd() you pass the addresss of a. Though, this function also has its own stact, any change in this function is directly on the stack of main.
So why would we do the latter. It is a tradeoff between immutability and efficiency. If you do not want to create thousands of stack frames with thousands of copies and essentially want to work (read: modify) on the variable a, then its more efficient at the cost of immutability.
Figma article is a great summary on horizontal partitioning
You must have hear of an auto incrementing ID,a hash ID or even a UUID to represent your database row as a primary key.
auto-incrementing are not suitable for distributed systems. HashIDs are not ordered by creation time, UUID are suitable for distributed systems but are random and feel meaningless.
A snowflake timestamp ID contains a timestamp + workerID(database instance) + sequenceID.
However, Unlike UUIDs, which are typically generated using pseudo-random or time-based algorithms, ULIDs combine time-based components with randomness to achieve uniqueness while preserving the ability to be sorted lexicographically
SHOW VARIABLES LIKE ‘innodb_buffer_pool_size’;

The limit allows you to separate description of an expression from the evaluation of the expression

Thanks to Maria Fusco devote talk
When you want to avoid updating a specific column in a table and your system is using ORM such as hibernate, some advise to set that column as update=false in the Entity.
The challenges to this is that someone may want to update this field in method1() but may not wish to do it in method2().
All the same, let’s revisit why the update=false is a good tool of Hibernate and what use-case fits best.
The point of updatable = false is to make hibernate not mess DB generated field values
You will see many folks doing something like this (say) to reduce a value from every element in a hash map.
inputCount.forEach((k,v) -> inputCount.put(k,v-1));The problem with this is that it is an anti-pattern with respect to the introduction to functional programming in Java. With FP, you don’t want to create side effects by doing modifications to an object that is being iterated.
The proper approach would be to make the modifications and collect them into a new data structure.
Map<Character, Integer> newMap = hashMap.entrySet().stream()
.collect(Collectors.toMap(Map.Entry::getKey, e -> e.getValue() - 1));Interesting that Supplier in the Functional Interface solves a specific problem of desiring lazy evaluation on a function.
If the function passed as a parameter does not have to be evaluated until some condition is met inside the called function, then pass that function-as-a-paramter as a supplier.
Before consumers of Log4j had to do something like
if(logger.TRACE.isenabled()) {
logger.trace(extractSomeFileHeavyFunction());
}
This is because the extractSomeFileHeavyFunction() is always called first and the result is passed as paramter to trace method only for the library to determine that trace is not enabled.
However, with the power of lazy evaluation of lambda paramters to a Supplier, you can do something like
logger.info(() -> extractSomeFileHeavyFunction());
In release 2.4
@Override
public void info(final Supplier<?> messageSupplier) {
logIfEnabled(FQCN, Level.INFO, null, messageSupplier, (Throwable) null);
}Due to the 2.4 and introduction of the supplier into their library, extractSomeFileHeavyFunction() will be lazily evaluated only after logIfEnabled is true inside the library
This is a good example of supplier – that adds another level of indirection – and brings java closer to functinoal programming – where you describe the operation instead of the value the operation produces
final Product firstProduct = Optional.ofNullable(product)
.orElse(productDao.findProductById(id));
final Product secondProduct = Optional.ofNullable(product)
.orElseGet(() -> productDao.findProductById(id));In the second case, of the orElseGet is not evaluated right away only if product is null. In the first case, it is evaluated right away so database is always queried. Another great example of lazy evauation
Consistency in microservices
compensation pattern – maintain another /delete API. So if an /order API does not have an equivalent record in payment microservice, you can use the order/delete API to delete the order.
Reconciliation pattern – If an order 123 has payment=false , then once in a while call an API on pament mircroservice to check the payment status of the order=123. If it is true, this means that it failed to send request to order MS, so mark order=123 in Order microservice to payment=true
application event log pattern – when having several microservices to book a trip – hotel, flight, payment, order, perhaps doing a reconciliation is too tedius. Use a log that is aware of all events.
container event
123 order_booked
123 pament_requested
This way, you can resume wherever the event failed.
Problem with all the above including application log event is complexity: single source of truth also needs compensation patterns.
An alternative is 2PC but the transaction coordinator can be a bottleneck if it goes down and cause scalability issues.

Please do not do this. It looks like a double negative
Here’s a great answer from Xenph Yan
In general, an index creates an additional table.
Some notes for above resource:
A linear search is done when there is no index. Although a linear search is sequential i.e for 1 million blocks (assuming each row is in a block), it should take 1 million accesses but on an average the data is always at the middle not at the extremes, so average case of linear search is N/2 i.e non-indexed search would take 500,000 accesses.
n contrast, the binary search algorithm takes advantage of the fact that the id field is sorted. It divides the search space in half at each step, effectively reducing the number of blocks that need to be accessed. This is why the binary search requires only 20 block accesses on average, which is a significant improvement over the 500,000 block.
log₂(x) = N where N is 1,000,000. X i.e the number of access is 20.
groupID and artificatID uniquely represent your project among all the projects in the world.
1.0.SNAPSHOT means its a work in progress version
In Node.js, the call stack works in conjunction with the event loop to manage the execution of asynchronous I/O operations. When an asynchronous function is invoked, it is offloaded to the Node.js runtime environment, allowing the event loop to continue processing other tasks. Once the asynchronous operation completes, the associated callback is placed in the callback queue, awaiting the event loop’s attention for execution. When the call stack is empty, the event loop will move the callback from the callback queue to the call stack for processing. This mechanism enables Node.js to handle asynchronous operations efficiently, maintaining non-blocking behavior and high concurrency
Over at this blog, a person asked how do distributed systems handle the same username going to two different database nodes of which both are leaders?
A reasonable answer he got is,
ou might want to read up on the CAP theorem. If you want to ensure consistency you have to sacrifice either availability or partition tolerance. It is not possible to get all three
But this response below really nailed it for me on why theorums like CAP try to achieve and how to appreciate them.
theorems like CAP (and halting problem for example) are useful because they tell you what you can’t do, then instead of wasting time trying to do that thing, you get to choose which thing that’s actually possible you want to do instead. On the other hand, people like to talk about these theorems a lot more than is actually useful because it makes them sound smart, which is why it doesn’t answer your question.
–
Reason data was normalized is because data storage was expensive. Storage is no longer expensive but CPU is. The problem with joins is that CPU goes crazy trying to pick up data from all corners of the disk.
The reason SQL does ACID is because data is in different tables. But if data was in a single table, you wouldn’t have to do ACID.
SQL does very well with OLAP storage engines i.e when you want to query for business intelligence – find me highest orders for those who have done payments regulary for each year except 2013 .This kind of query is difficult to model on noSQL. NoSQL does well with OLTP. Dynamo DB can do 4 million transactions per second.
Advantage of NoSQL liek Dynamo DB is that not only is the storage modelled in a way that fits the access pattern – get me all warehourses with the highest orders so warehouses is the partition key and orders is the sort key – but that when the data is hashed according to the partition key, all the data goes into the same node. Hence when data is queried, the DB engine needs to only search in one node and is faster even when you scale.
As there is replication due to clustering, you have eventual consistency. DynamoDB with secondary indexes gives you strong consistency and eventual consistency with global indexes.
Some of the antipatterns in nosql is when you see your red heat maphot partition(server) one storage not the rest. This is because of low cardinality. You cant have a partition that has yes/no values. This would disproportionately add all values to a single partition node making most of the queries go to one node. UUIDs are good way of randomly – and hence uniformly – distributing data across several partitions.
Partitions are like servers. Here is some foundation on partitions
When an Amazon DynamoDB table is created, you can specify the desired throughput in Reads per second and Writes per second. The table will then be provisioned across multiple servers (partitions) sufficient to provide the requested throughput.
You do not have visibility into the number of partitions created — it is fully managed by DynamoDB. Additional partitions will be created as the quantity of data increases or when the provisioned throughput is increased.
Let’s say you have requested 1000 Reads per second and the data has been internally partitioned across 10 servers (10 partitions). Each partition will provide 100 Reads per second. If all Read requests are for the same partition key, the throughput will be limited to 100 Reads per second. If the requests are spread over a range of different values, the throughput can be the full 1000 Reads per second.
If many queries are made for the same Partition Key, it can result in a Hot Partition that limits the total available throughput.
Think of it like a bank with lines in front of teller windows. If everybody lines up at one teller, less customers can be served. It is more efficient to distribute customers across many different teller windows. A good partition key for distributing customers might be the customer number, since it is different for each customer. A poor partition key might their zip code because they all live in the same area nearby the bank.
The simple rule is that you should choose a Partition Key that has a range of different values.
Does userID chosen as partition key for userids 1-1000 mean mean there will be 1000 partitions?
Design pattern for computes
MongodDB has aggregates but they don’t scale. The trick in NoSQL is to offload CPU. So aws lambda are like procedures because the run on the data. If you have a lambda streaming you data when it is written, you can aggregate that data and write it back to the table. This way, you are saving the compute on the fly and it can be read by millions without having to re-compute it.
Did you know that your OS sets accept-language headers automatically when you visit a site? It even sets ths tag with multiple languages with a form-factor q between 0-1 to tell the browser what languge you prefer the most.
Accept-Language:
es-ES,en-GB;q=0.8,en-US;q=0.7
default methods in interfaces give you an impression of multiple inheritance. the interesting point is that it gives you the powers of multiple inheritance of behavior but not state.
if the array has 1000 elements, binary search will take around 10 steps.
The relationship between the number of elements and the number of steps can be mathematically explained using the concept of logarithms. In the case of 1000 elements, the base-2 logarithm of 1000 is approximately 10, which means that binary search will take around 10 steps to find the desired element
Log base 2 is the power to which the number 2 must be raised to obtain the value of n. For any real number x, log base 2 functions are written as. x = log2 n. Which is equal to. 2x = n.
A p99 latency means that 1% of the web requests were expected to be slower than the usual. So if p99 is 1.3 seconds and p95 is 0.5 seconds, this means that there are 1% requests that are spoiling the chart and giving an incorrect impression that the latency is high. When these initial load, cache warm-up requests are cut out from the picture by doing a p95, it gives a better idea of the average latency for 95% of the requests: 0.5 seconds.
Functional programming in Java was introduced and people began to use Java Stream, lambda expressions with motivation that it’s a great way of doing SQL in Java or imperative is better than declarative for loop.
The truth is, it solves immutability
The command pattern has a client , receiver and a command. the receiver object is the type that represents the business logic of an application. The responsibility of a command is not to own the business logic, but to expose this business logic to clients using a common and standard interface, i.e. the execute method. Then, I think that the receiver is not merely a relic of C/C++
The runnable interface in Java is an example of command patterns where the business logic is exposed to the client through the standard run method.
This is an award winning strategy pattern explanation
If you have two or multiple ways of doing things, you can wrap it into a strategy
e.g two ways of processing a day of the month via AndroidMathTime and via JavaCalendar
The best selling point about associations in JPA are: do not expose data layers for an Address if an Address only belongs to a customer. This way, you won’t headless Addresses.
Here are two articles that talk about this. One to maintain loose coupling and another, to explain aggregate pattern in JPA
In Domain Driven Design, the domain is at the heart of the application. The domain is itself not used for persistence. Not using Tools like JPA well can lead to using the same artifact (e.g java class) as domain model and persistence model thus mixing infrastructure with business.
Here’s a good series that reviews how well JPA as a tool is domain driven
function doSomething() {
return Promise.resolve('#2');
}
const promise = doSomething().then(console.log);
console.log('#1');This will print 1 before 2 because doSomething() returns a promise and hence the flow passes to console log(1) immediately. then() is non-blocking
async function doSomething() {
return '#2';
}
const result = await doSomething();
console.log(result);
console.log('#1');doSomething is now an ‘async’ function. It returns a promise internally. Using await is a cleaner way of receiving a promise. If await is not used, then the promise needs to be accessed using then(data=>) construct.
The await is blocking, so 2 is printed before 1.
function doSomething() {
return Promise.resolve('#2');
}
const promise = doSomething().then(data => {
console.log(data);
console.log('#1');
});doSomething() now is not an async function but it explicitly returns a promise.
async function doSomething() {
return '#2';
}
const result = doSomething();What happens in this case? result will hold a promise. This is because an async function internally returns a promise with the value from the return statement already resolved. If you want merely print 2 instead of holing the promise in result var, await doSomething()
Async await makes promises totally internal
Examples were taken from Vinicius’s post, Please follow there for detailed explanation
Promises is an older java script feature than async-await. Code in many libraries looked like this
function getData(callback) {
setTimeout(() => {
callback('Data received');
}, 1000);
}
getData((data) => {
console.log(data);
});It had to be rewritten to support async-await as
function getData() {
return new Promise((resolve) => {
setTimeout(() => {
resolve('Data received');
}, 1000);
});
}
async function main() {
const data = await getData();
console.log(data);
}
main();Another example is code that looked like this in libraries
function getData() {
return new Promise((resolve) => {
setTimeout(() => {
resolve('Data received');
}, 1000);
});
}
getData().then((data) => {
console.log(data);
});Which was turned into
async function getData() {
return new Promise((resolve) => {
setTimeout(() => {
resolve('Data received');
}, 1000);
});
}
async function main() {
const data = await getData();
console.log(data);
}
main();When you want to display jpa repo queries under the hood, hibernate.show-sql doesn’t work.
_Worker-2] find using query: { “imsClientID” : “local2”, “active” : “YES”, “exportEndDate” : { “$lte” : { “$date” : 1705038749807}}, “statusEnum” : “OPEN”} fields: Document{{}} for class: class com.
In the logback xml add
<logger name="org.springframework.data.mongodb.core.MongoTemplate" level="DEBUG" />
If you are not using any logger library, you can add this same in the yaml file as
logging.level.org.springframework.data.mongodb.core.MongoTemplate=DEBUG
One nice thing I learned from this clean architecture video is that all dependencies point inwards towards core services.

This means , the author says that it would be a horrible mistake to hardcode a stripe paymentgateway directly being called on the simplepaymentservice class. This would make the core service i.e SimplePaymentService point outward ice point towards the StripePaymentGateway class instead of the other way round i.e StripePaymentGateway points towards classes that point towards SimplePaymentService, so the coreservices never change. all of them somehow
As a corollary, We have a UserService that calls our most important User table. Every component should call UserService because it needs access to user data but UserService itself should not have to call (say), PaymentGateway because it doesn’t implement anything rather other services call it. This is a great example of boundaries i.e like a micro service pattern. The inner layer should not know about the outer layers calling it and so, immune to changes on the outer layer. The outer layers should not be aware of DTOs used by inner layers.
watched an interesting video of visitor pattern. In stead of adding sendEmail() into your abstract class and having your child classes implement them, a visitor pattern separates the behavior of sending email from the objects it operates on.
I liked the idea that instead of doing

The visitor pattern can achieve sending email by simply doing

So why do this when you can simply let child classes implement this sendEmail()
interesting observations by people
If i need to change the way the mail is send for a resident, i’ll need to go to the visitor and update, the same is true in case of the original design where i’ll change the sendMail behaviour. If i am creating multiple visitors like send mail and another which is give promo, I’ll need two different function in the client to call the correct visitor. How is this any different from the initial class structure?
answers:
n the initial structure, if you want to modify the behavior of your classes (the ‘sendMail’ functionality in this case) you’ll have to open and break each and every child class you have. After applying the Visitor pattern, the only change you need to make will be inside your visitor, your classes are now closed for modification but open for extension. Hope this helps!
The visitor pattern solves the double dispatch problem not just writing cleaning code. the latter is secondary,
REST decouples client and server unlike SOA through HATEOAS
Do you also run background jobs on the same web server that serves your user requests?
In a JVM environment, the CPU makes sure it evenly distributes time so that even if you have a long running task (LRT), your web request get served too. This does not mean the long-running tasks may not have a negative impact. In fact it is possible that if the LRT is memory intensive, it could result in GC pauses.
Only measuring and observability can let you determine if you need a separate server to act as a job server.
A good hack to ignore unknown or unrecognized fields when mapping a JSON to an object is to use
@JsonIgnoreProperties(ignoreUnknown = true)The MySQL buffer pool contains not only the index but also the row referred to by the index How? The index are stored as B-Tree and the actual data(row) referred to by the index are leaves of the tree. This is known as clustered index in MySQL.
This is why indexes are fast. Refer this article to see how indexes work in MySQL
Why is indexing fast? Without an index the DB needs to read each record i.e a table scan. With indexing, the field is converted into a binary tree. Now, a search for any element in n elements returns a logarthmic time much like searching for a name in a phonebook.
Future is blocking.
With completableFuture, you could do something like
CompletableFuture<Integer> c =
CompletableFuture<Integer> 2 =
CompletableFuture<Void> done = c.thenApply(i->i+1).thenCombine(cf2,Integer::sum).thenRun(()->{/**/};As futures are blocking, you would first have to collect all the values returned by c in a blocking queue, then schedule something to read them…
A wonderful thing about keeping your API requests below 100m/s is that it gives you a simple metric that with a 100 tomcat threads and benchmark of 100m/s, your server can handle 1000 concurrent requests/second.
That’s little’s law L = λW where L is the total
L is the no. of workers (threads)
λ is the thoroughput or the new requests per second (that can be serviced)
W is the average time taken to service each request
λ = 100/1000 ms = 1000 concurren requests/sec
Take the example of java tomcat container on JVM, Maximum concurrent requests it can handle is around 2000. This is because JVM runs on a thread per connection model and at around 2000, it is unable to service all of them at the same time.
With reactive Java (say), you can beat this problem often known as the c10K problem i.e running 10K concurrent requests per second. Some have even implemented beatng C100K and even a million concurrent requests per second.
However, the code complexity is the tradeoff. Imagine the skills required to write something like this and to have your team understand it .
The below example is taken from Tomasz Nurkiewiczs lesson’s learned talk
A simple shopping cart example,

If you want to make sending emails concurrent, reactive programming does it as below.

When a team builds their redis structure, they now look to leverage search. Redis, especially redisJSON provides great support for search.
However, there are times when one wants to do a value based search (as opposed to key-based). Look for services like ElasticSearch instead.
Has redisJSON already overtaken redis hset? Is there any use-case where it is better to stick flattening an object using HSET as opposed to simpl use redisJSON?
One of the ways redis is a good use-case for older and slower systems of record is that the query is used as the key and the serialized result set as the value. This saves lots of effort in migrating old systems.
in spring security stateless policy, OAuth server does not store any session information on the server side, instead relying on a self-contained token to authenticate the user. The server verifies the token on each request to ensure that it has not been tampered with or expired. Stateless OAuth removes the need for the server to maintain session state, which can improve scalability and reduce the risk of security vulnerabilities.
Having said this, if you look at your response header, it will still have jsessionid=
This is because the session will always be injected (and created if one doesn’t exists) if you request that, that has nothing to do with setting Spring Security to stateless. That is only a setting for Spring Security NOT the remainder of your application. If you are using JSP you will get a session always and depending on your controllers that also might create a session.
If you use a controller such as
@PostMapping
public void create(HttpSession session) {}
The session will always be created because of the argument. If you don’t want it to be created, use HttpServletRequest
data restoration recreates procedures adding the msqluser of the devops guy as definer. When the jdbc user of your app calls the procedure, it has no rights to use the procedure.
I wish there was an easy way to run a command and cleanup the definers of a procedure.
We’re doing hourly data export for a customer. So we export data say, between 12:00-12:59:59 & 13-13:59.59. The datetime in mysql would be yyyy–mm-dd hhmmss that is covered in the range for any data’s createdDate/modifiedDate
Gotchas arrive when you realize that MongoDb prefers to future proof and save date in 64-bit ie hhmmss.xxx So our range would miss data like 12:59:59.389
When we upgrated to spring boot, we kept our spring mvc instance running as disaster recovery.
This means we had to test clustering use-cases such as quartz scheduler to run seamlessly on mvc and boot.
True enough, we had issues and had to revert. Always plan for recovery.
Does redis take a backup of its ephemeral data? Yes. But beware
During snapshot redis will fork the process and dump what is in that forked process to disk. This means you need 2x the ram to perform this action but also it’s a global db lock during the forking process. If you have a small dataset this generally fine but if you have a large db this process will cause large spikes in latency when the snapshot begins.
A good sql coding exercise is to ask people to find how which user contacts are missing in UserContact Table but present as Users in User tabe.
This shows the person’s prowess in LEFT Join. The exercise can increase one level in complexity when UserContact now does have a contact but it is not of type Personal. So you’re only looking for those Users from User table that are missing their own contact in the UserContact. Thus, you could join with the UserContact table (in principle) but it’d still not do because the join could be successful because the contactType is (Say) User’s PCP (primary care physician) instead of PERSONAL.
select User.UserID,User.ClientID ,User.UserTypeID, User.firstName,User.lastName, UserContact.ContactType
from User left join UserContact on User.UserID = UserContact.UserID
and UserContact.ContactType = 'PERSONAL' where ContactType is null;There ‘s a good point to be made here, especially when exportng your MySQL database to something like MongoDB that has ObjectID as primary key instead of integer.
auto-incrementing keys as API resource identifier expose your database technology etc.
I will add a point (that happens to be referenced here) that they also tempt the client to check if that can query songs/2 instead of songs/1 to see what they get. So now you’re security policy is under test where as with, uuids a malicious or erring client that does songs/4563-3232-ert34-342fs for songs/1 will not be able to know what the corresponding uuid to songs/2 is.
learned a lot from an assignment I did on finding the nearest car park. Here’s a great blog explaining geo spatial types in MySQL. This percona site also explains geometric planes
Eventually ended up using
select ST_Distance_Sphere(
point(-87.6770458, 41.9631174),
point(-73.9898293, 40.7628267)) where point(longitude, latitude) where lat, long can be saved in decimal in the DB.
If you are trying to find nearest distances for short distances between say 20 kms, it is ok to use eucledian distance. Beyond that, desiring exact differences needs to take the earth’s spherical curve into account i.e the shortest distance is not a straight line from point a to point b.
All the same the above ST_Distance_sphere gives the minimum spherical distance in meters.
fundamental understanding of how a spring proxy works in transaction
Spring transactional only works on bean methods not if you call a method of your own class i.e both methods belong to the same object.
Spring transactional doesn’t play well with protected and private methods.
Spring transactional is propogation required by default and also is turned on if you have spring-data-starter on your classpath
Created a docker compose yml that defines the relationship between different services. However, no matter how man times I hit docker-compose up, it brought the same containers up.
version: '3.1'
services:
db:
image: mysql:8.0
restart: always
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: testdb
MYSQL_USER: user
MYSQL_PASSWORD: password
ports:
- 3306:3306
volumes:
- db_data:/var/lib/mysql
web:
image: assignment
build:
context: .
dockerfile: Dockerfile
ports:
- 8080:8080
depends_on:
- db
environment:
SPRING_DATASOURCE_URL: jdbc:mysql://db:3306/testdb
SPRING_DATASOURCE_USERNAME: user
SPRING_DATASOURCE_PASSWORD: password
SPRING_JPA_HIBERNATE_DDL_AUTO: update
volumes:
db_data: {}The trick is to build docker image.
docker build --build-arg JAR_FILE=build/libs/*.jar -t assignment
.–build-arg indicates that there are multiple arguments
Now when you run docker-compose to start all your services you will see this

It has picked up your changes
great resource here
Open your spring boot application And do the following
On intellij, open your terminal > git init
The above will create an empty git project into which you can add your files. To add all your files in one shot, use
Create a GIT VCS repo

Intellij requires that you let it know that you have a VCS repo. press the + symbol and select your root directory and mention that it is controlled by GIT
git add .
You can then commit then doing git commit -m “inital commit”
Meanwhile, you must create a new git repo in your github account. Once that is done, you will have the repo link on the top of your page. You need that on your editor.
Add this command to the git terminal
git remote add origin <repository_url>
Finally, we are ready to push the files. When you push the files, you will need persmission to push it to this repo. Intellij throws a login prompt. But this login prompt does not work. It seems intellij has made all github accounts login via token.
To create a token, go to github > settings > developer settings > personal access token > fine grained token > create token for a specific repo > add repo permissions like read & write. MAKE SURE YOU SAVE YOUR TOKEN SOMEWHERE. Github will not show you that token again.
Back to intellij. when you try to run the push command, it will prompt a dialog box.

close this box. This will then prompt git terminal to throw a cmd prompt for user and password.
The password you need to enter according to intelliJ is the token you created and copied to clipboard. paste in the place of the password and your files will be pushed.
You will get a 401 if your password is wrong or if you add github account password. You will get a 403 if the token you generated has no write access to the repo.
Thanks to Gayan Madhusankas blog at medium which I followed for the git terminal commands
Lets say you want to

If you only want to MobileApp… file then open that file > right click open in teminal on intellij IDE. you will see the terminal having the same directory as the file above.

Now we have only two files that need to be committed


When mysql is not set in the windows path directory, it’s easy to get this when running a shell script.
I tried adding many keys to environment variables but it didn’t work.
this resource worked for me. Essentially set the path of the mysql folder that contains msql.exe. In my case it is not MySQL 8.0 but MySQL 5.7 so I did
SET PATH=C:\Program Files\MySQL\MySQL Server 5.7\bin;%PATH%
next thing you know, mysql is detected just by typing it.

Simon Martinelli presents a talk on JOOQ. One of the ideas he mentions is that if you have an old ERP with 2000 tables and a few thousand procedures, Hibernate wil not work because you cannot create one thousand entities just to map with the procedures. JOOQ well instead.
No wonder they say we should read books. Here’s an interesting article recapping how transactions work and why the default autocommit mode which is true for JDBC is false when ORMs like hibernate are used as a wrapper above JDBC. Hibernate forces you to think of your database statements as business logic to which you need to define a boundary i.e a transaction so that connections are not opened and closed for each statement.
C3P0 closes unreturned (to the pool )connections . But hikariCP has used a different ideology.
HikariCP does not, in principle, believe that the pool should coverup connection leaks. We disagree with the reasoning behind C3P0’s unreturned connection handling.
The leak detection is there to help you pinpoint the source of the leak. That should provide enough clues to track down the configuration or coding error.
This post explained to me why, Sometimes, I could see my connection pool go to 0 from 50. Long ignored it but realized one shouldn’t ignore anything.
HikariPool-0 (total=100, inUse=0, avail=100, waiting=0)
HikariPool-0 (total=4, inUse=0, avail=4, waiting=0)I was installing apache so that I can run the tool ab

if It doesn’t throw you such a page, the most probably it also threw some error while starting. In my case, I went to bash and to the bin folder and ran
./httpd.exe(OS 10048)Only one usage of each socket address (protocol/network address/port) is normally permitted. : AH00072: make_sock: could not bind to address [::]:80
(OS 10048)Only one usage of each socket address (protocol/network address/port) is normally permitted. : AH00072: make_sock: could not bind to address 0.0.0.0:80
AH00451: no listening sockets available, shutting down
AH00015: Unable to open logs
netstat -aon | findstr :80Above will show which process is listening on 80. You need to kill it so that apache can run on 80.

So I had to find out what’s running on 80 and then kill it.
tasklist /svc /FI "PID eq 17352"ERROR: Invalid argument/option – ‘C:/Hi/Tools/Git/svc’.
Type “TASKLIST /?” for usage.
I don’t require it so I killed it. First I tried
taskkill /pid 17352 /fBut it wouldn’t die so I force killed it by
taskkill -F //pid 17352Run ./httpd.exe and I got the ‘it works’ message.
Hadto fork out a new branch because a merge ruined a feature branch. The issue is that one needs to know from what commit id to create the new branch.

The issue with intellij or even gitK command is that it can be difficult to know what commit was on which branch.
git log master..dev
command allows you to see all commits on dev that are not present in master. So if dev was forked from master, you would be able to see all commits of dev stacked without the cumbersome tree confusing you.
if you have messed up your branch say dev, then one way out is to start a new branch fom the commit where everything is OK
on intelliJ you can right click on the commit and say “start new branch”
As your new branch is not the “real dev”, you could try to rename it
git branch -m dev-backup dev
fatal: A branch named ‘dev’ already exists.
But the origina “dev” still exists so you will have to delete this local branch.
You can right click on the local dev branch and choose delete
run this again and it will work git branch -m dev-backup -dev
But the branch on remote that is still broken exists as “dev” where as your new clean branch is also called dev. Time to delete broken dev from remote (origin)
git push origin –delete dev
— git says [deleted] dev
now free the branch dev that you just created from any upstream tracking
git branch –unset-upstream dev
push your new local branch to remote
git push origin dev
set up local dev to track upstream dev
git push origin -u dev
nice writeup on remote tracing branch
The default setting is 4M and the docs say “As it is flushed once per second anyway, it does not make sense to have it very large (even with long transactions)”. There’s another option innodb_buffer_pool_size (looks similar) for which 800M makes probably more sense (docs: “The bigger you set this the less disk I/O is needed to access data in tables”).
limits your architecture to layers in such a way that makes your classes into wrappers of db-schema
How will your system react if a celebrity tweets that has 30 million followers? Would it do 30 million writes into the time line cache of its followers? Such factors – a celeb tweeting – can be considered load factor.
steps to take for Reliability – can your stem undo changes it has computed? Can you rollout changes onlto a subset of data?
Seems like mongodb export does not select all columns from a document but only picks up fields from samples
SalmanShariaty mention a way to use an aggreagation pipeline to get all the fields in all documents. I nuance it futher for novices to know how to execute the pipeline
db.collectionName.aggregate([{$project: { arrayofkeyvalue: { $objectToArray: '$$ROOT'} }},
{$unwind: '$arrayofkeyvalue'},
{$group: { _id: null, allkeys: { $addToSet: '$arrayofkeyvalue.k' } }}])Kafka can send a message on particular partition. A partition of a topic is just a consumer of that topic. You could have two partitions if the two consumers do different things e.g one updates a dashboard, second sends a notification.
Kafka can even send a message on a key e.g gold-commoditiy. All message of gold-commodity then go to that particular commodity.
From web, we reach the BasicAuthenticationFilter. Here
if (this.authenticationIsRequired(username)) {
Authentication authResult = this.authenticationManager.authenticate(authRequest);
if (debug) {
this.logger.debug("Authentication success: " + authResult);
}
SecurityContextHolder.getContext().setAuthentication(authResult);
this.rememberMeServices.loginSuccess(request, response, authResult);
this.onSuccessfulAuthentication(request, response, authResult);
}At this point of the code, the authentication managers attached to the filter will authenticate the details provided. E.g if you have attached a DaoAuthenticationProvider as authentication manager, then it goes to the authenticte method in the AbstractUserDetailsAuthenticationProvider that it extends from.
user = this.retrieveUser(username, (UsernamePasswordAuthenticationToken)authentication);here it will allow you first 1) do a check on your client if it exist. So username is name of client . This will go to interface ClientDetailsService which as a single method loadClientByClientId(). You can implment this interface and load the client the way you want i.e either from memory or database.
Once the filter works and all is good with your client ie all pre and post authentication checks such as client account not expired, password is good etc, the request reaches /oauth/token endpoing in TokenEndpoint class.
Here the token granters – password, implicit, clientcredential token granter, auth code granter will check for what oauth flow is your token being requested for. That particular class will then prepare your token.
The abstract Token granter will call the grant method and prepare the client and the tokenrequest.
public OAuth2AccessToken grant(String grantType, TokenRequest tokenRequest) {
if (!this.grantType.equals(grantType)) {
return null;
} else {
String clientId = tokenRequest.getClientId();
ClientDetails client = this.clientDetailsService.loadClientByClientId(clientId);
this.validateGrantType(grantType, client);
if (this.logger.isDebugEnabled()) {
this.logger.debug("Getting access token for: " + clientId);
}
return this.getAccessToken(client, tokenRequest);
}
}to retrieve user from Database if you have implemented the UserDetails interface
Once the getAccessToken is called it will go to the specific token granter class. e.g in this case, it is the ResourceOwnerPassword granter.
protected OAuth2Authentication getOAuth2Authentication(ClientDetails client, TokenRequest tokenRequest) {
Map<String, String> parameters = new LinkedHashMap(tokenRequest.getRequestParameters());
String username = (String)parameters.get("username");
String password = (String)parameters.get("password");
parameters.remove("password");
Authentication userAuth = new UsernamePasswordAuthenticationToken(username, password);
((AbstractAuthenticationToken)userAuth).setDetails(parameters);
Authentication userAuth;
try {
userAuth = this.authenticationManager.authenticate(userAuth);
} catch (AccountStatusException var8) {
throw new InvalidGrantException(var8.getMessage());
} catch (BadCredentialsException var9) {
throw new InvalidGrantException(var9.getMessage());
}
if (userAuth != null && userAuth.isAuthenticated()) {
OAuth2Request storedOAuth2Request = this.getRequestFactory().createOAuth2Request(client, tokenRequest);
return new OAuth2Authentication(storedOAuth2Request, userAuth);
} else {
throw new InvalidGrantException("Could not authenticate user: " + username);
}
}Once you reach this class, it will do an authentication again. as shown
this.authenticationManager.authenticate(userAuth);As we see, I have two authentication managers

This is because the default configured – serverWebSecurityAuthManager will be used for web requests. For a certain case, we are internally generating an oauth token. Thats right, this token is generated without going to request /oauth/token. For such cases, we are maintaining a separate authentication manager. This is because for such request that have not passed through any of the filters, there will be no context saved in any of the filters e.g SecurtityContextHolder. As we can’t take advantage of it and we don’twant to mess up the implementation of auth manager of web requests , we create our own one.
The authenticationManager of the ResourceOwnerPasswordGranter is injected by WebSecurityConfigurerAdapter. That’s why the authenticate method inside ResourceOwnerPasswordGranter will make a round trip first to extract all the providers and then the authenticationManagers. But the defalt authentication manager is DaoAuthenticationProvider, so that is where we will eventually land again.
So we are back in the AbstractUserDetailsAuthenticationProvider class to authenticate the user but this time with username that he presented during login.

As the user mentioned in line 66 is class UserDetails from springframework,
public interface UserDetails extends Serializable {
Collection<? extends GrantedAuthority> getAuthorities();
String getPassword();
String getUsername();
boolean isAccountNonExpired();
boolean isAccountNonLocked();
boolean isCredentialsNonExpired();
boolean isEnabled();
}So what preand post authentication checks do below is to check if the account(user account) is still locked, enabled, expired etc.

If everything is good, as you see below, it will return an Authentication object to ResourceOwnerPasswordTokenGranter class that started the flow object from which a token will be created.

Authentication is an interface but userAuth will eventually contain an implemented class object e.g UserNamePasswordAuthenticationToken

Both Oauth2Request and auth object have similar details – principal, credentails, scope, authorities, client etc.
After this is the last part where we are back in the AbstractTokenGranter? How? because the tokenGranter simply creates a token but it reuires an authentication object. This was given to it by the ResourceOwnerPasswordTokenGranter that got it an authentication object after doing authentication etc.

Now the token granter can simpl acess the tokenservices to find the token services details – access time, token enhancers e.g adding new things to token and any token converters e.g encryption, signing key etc.
So this is the last part where the access token and refresh token is returned

Things I learned from a good conference I watched by Jimmy Bogard on Microservices
microservices & owning the shape of the data – But if you’re going to have a search microservice, it needs to own the shape of the data in such a way that it can return the search results without having to make a hop to another microservice in which the data is stored in a legacy fashion on which it would be impossible to add any kind of searching. So the way out is that instead of having the search microservice query all other microservices, you inverse the dependency


So if they call you, you have all the data and the search API can now get faster. Data is duplicated but duplication of data solves many problems.
Another good things about this talk is that he tears apart the paradigm that tons of talks promote which still describe micro-services along the one-database per service and you have to do tons of APIs calls and have services calling other services. That is why Kafka and other messaging technologies don’t show up in their designs/talks. Because the Kakfa way, the consumer (say insurance app) would receive the data from a source of truth (say customer change) and can then just present data to its consumer (say an email about policy changes).
There is generally one “system of record” and common to have many “sources of truth” for the same data. Not all sources of truth must be in sync with each other, but that’s an SLA that the architect must decide. The system of record is the system that owns the data. A source of truth is just a system that can be trusted. A caching layer can be a source of truth.
provisioning infrastructure in a consistent repeatable manner via code that is declarative stored in version (like github), its idempotent (if someone deploys again, it should not change the state if nothing has changed).
This leads to documented architecture
the previous MongoDB engine buffered some space on disk for future documents so that the entire collection can be in the same disk space. Very interesting.
A model is a logical representation of data. A schema is more concrete representation of that data related to a database engine
design according to purpose – what is being built Survey?
Decision to design collections: Ownership is important. Person and Adress can reside in the same document. But photos of a person has its own lifespan – likes, comments etc. Change velocity is another, photos change a lot, a person’s name and address may not.
Another advantage of survey is history. When you change/add a question in relational DB, what happens to (say) a survey that is linked to a question table but now has an additinoal question that a previous survey taker did not answer? unstructured data solves this. The previous survey will have its own json of question + answers together as one document. It does not reference the survey question collection.
restaurant{
"Name":"Glitter",
"Location":34354345,
"Latitude":34353
}This is usually a code smell because it looks more like a tabular SQL representation for mongoDB. we could easily add lat and long in to an object
restaurant{
"Name":"Glitter",
location:{
"Location":34354345,
"Latitude":34353
}
}Anti patterns of modelling

if you want to model lunch groups and you create a collection where you couple restaurant blocks with crews, it looks like an anti-pattern due to following characteristics
ownership, lifetime, change velocity and structure.
Whole idea of document is to encapsulate all working data in one document.
A company of product may change it’s name. It’s interesting how in SQL, if you allow a products name to be changed, a historical document that has a product ID referencing product table will show the new name instead of showing the historical name on which the bill was generated. In such cases, either we have to create a new product to maintain the older product version – which has its own issues or a noSQL document can contain the id and name there by always showing the product name in the historical context.
One to few relation
You could have a document that has a one (crew) to few (people) relationship.

What you should consider is, if it is right to put a fan list for a music playlist. That could be a one to few that may hav a million fans. Documents have size limits.
One to many
If there was photos [] array inside the restaurant, over time, it can grow and perhaps is not the best consideration.

One way to bring in all photos conforming to the ‘one-shot’ princple is to keep recent photos in the same restaurant document
Sharding
If you design documents well, you can shard (partition) well.
idempotence, versioning, location independent and immutability

The first concern of the architect is to make sure that the house is usable, it is not to ensure that the house is made of bricks.
In DDD – use-cases, usability are essential. Persistence, presentation are implementation detail.
Criteria criteria = new Criteria();
criteria.orOperator(Criteria.where("StatusEnum").is(StatusEnum.FAILED),Criteria.where("StatusEnum").is(StatusEnum.OPEN));
Query query = new Query(criteria);
List<MyMongoDbCollection> myMongoDbCollectionEvents= mongoOperations.find(query, MyMongoDbCollection.class);Spring Rest template works out of the box when the response is JSON. It’s opinionated and easy. The trouble begins if you want to extract a response that is not JSON. In this case, the deep dive in knowing about message converters can make one dizzy.
In the opinionated case, to consume post to an API endpoint and consume the response can be as simple as
UriComponentsBuilder builder = UriComponentsBuilder.fromUriString(webhookURL);
URI ApiUrl = new URI(builder.buildAndExpand(urlParams).toUri().toString());
ResponseEntity<Object> objectResponseEntity = integrationAppRestClient.postForEntity(ApiUrl, payloadObject, Object.class);
Object body = objectResponseEntity.getBody();
return objectResponseEntity.getStatusCodeValue();The above is Build API Url -> Post Response – > get status
But if the verbose non-opinionated – say if you want to consume a html response – will be
Charset utf8 = Charset.forName("UTF-8");
MediaType mediaType = new MediaType("text", "html", utf8);
headers.setContentType(mediaType);
HttpEntity<Object> httpEntity = new HttpEntity<>(postResponse, headers);
UriComponentsBuilder builder = UriComponentsBuilder.fromUriString(webhookURL);
ApiUrl = new URI(builder.buildAndExpand(urlParams).toUri().toString());
MappingJackson2HttpMessageConverter converter = new MappingJackson2HttpMessageConverter();
converter.setSupportedMediaTypes(Collections.singletonList(MediaType.TEXT_HTML));
integrationAppRestClient.getMessageConverters().add(converter);
ResponseEntity<String> objectResponseEntity = integrationAppRestClient.exchange(ApiUrl, HttpMethod.POST, httpEntity, String.class);
return objectResponseEntity.getStatusCodeValue();Set the headers -> Create an HttpEntity as you are now going to add (headers, payload) together as an entity -> set the converters that will consume the html response -> make sure the final respone can consume the HTML as string so set String as return type
So that’s the overhead.
In the spring-web HttpMessageConverterExtractor class, here is where most of the magic takes place and most of the exceptions that “there was no suitable converter found for response” will originate from.
public T extractData(ClientHttpResponse response) throws IOException {
MessageBodyClientHttpResponseWrapper responseWrapper = new MessageBodyClientHttpResponseWrapper(response);
if (responseWrapper.hasMessageBody() && !responseWrapper.hasEmptyMessageBody()) {
MediaType contentType = this.getContentType(responseWrapper);
try {
Iterator var4 = this.messageConverters.iterator();
while(var4.hasNext()) {
HttpMessageConverter<?> messageConverter = (HttpMessageConverter)var4.next();
if (messageConverter instanceof GenericHttpMessageConverter) {
GenericHttpMessageConverter<?> genericMessageConverter = (GenericHttpMessageConverter)messageConverter;
if (genericMessageConverter.canRead(this.responseType, (Class)null, contentType)) {
if (this.logger.isDebugEnabled()) {
ResolvableType resolvableType = ResolvableType.forType(this.responseType);
this.logger.debug("Reading to [" + resolvableType + "]");
}
return genericMessageConverter.read(this.responseType, (Class)null, responseWrapper);
}
}
if (this.responseClass != null && messageConverter.canRead(this.responseClass, contentType)) {
if (this.logger.isDebugEnabled()) {
String className = this.responseClass.getName();
this.logger.debug("Reading to [" + className + "] as \"" + contentType + "\"");
}
return messageConverter.read(this.responseClass, responseWrapper);
}
}
} catch (HttpMessageNotReadableException | IOException var8) {
throw new RestClientException("Error while extracting response for type [" + this.responseType + "] and content type [" + contentType + "]", var8);
}
throw new RestClientException("Could not extract response: no suitable HttpMessageConverter found for response type [" + this.responseType + "] and content type [" + contentType + "]");
} else {
return null;
}
}You have an token API that has been provided by a third party. You try it on postman and it does not work. luckily, it occurs to you to use another API tool, curl. You call the same API on curl and it works!

Thats how important tooling is. If you were to be familiar only with postman, you may have shot an e-mail for support.
@Value("${security.oauth2.authorization.jwt.key-value}")
private String signingKey;
security:
oauth2:
authorization:
jwt:
key-value: thisispasswordstringOf couse the class should be managed by Spring with @Component /@Service
We have some code on controller where we pick up the client attribute saved in the session when user is logged in.

If the attribute is not found, we assume tomcat expired the session and we redirect to login page.
Issue is that on every refresh of the page, the session kept changing and after a while tomcat was clearing older sessions that contained the client data. Thus our page kept logging off. Why did tomcat refresh the sessionID on each page request?
Spring security by default adopts a strategy to prevent session fixation attack.

Through tomcat, I found


yesterday AWS showed high I/O for one query. It was picking a single row from half a million records. As the field was not indexed, it was spending lots of time in disk I/O. Did some quick reading on I/O.
As you probably know, RAM is fast for I/O and disks are comparatively slow. If every operation MySQL server needs can be fulfilled in memory, you’re going to have a good time. If every operation results in a read or write to disk, you’re going to have a bad time. In reality there will be a mix of both as data is persisted to disk, but in general you want to configure your server to do as much work as possible in memory.
TLDR;
You don’t want your load to increase, that is queries bottling up just because the engine is taking data from disk which is slower inorder to prepare its resultset.
In MongoDB, you can use the db.collection.totalIndexSize() helper, which returns data in bytes telling you the size of your index in memory giving you a good idea of how tuned your collections are
Above text is taken from this article. It is a really good article to understand some fundamentals on database optimization
1) Which technology satisfies the requirement of the application ?
2) Learning curve for that technology
3) Resource availability for that technology ie directly related to training and maintenance cost of the application .
4) Ease of adaptability and future of the technology .
5) Licencing cost if any .
6) Some time personal preference

They look like this which is a combination of
ObjectId(4 bytes timestamp, 3 bytes machine id, 2 bytes process id, 3 bytes incrementer)
Intuitively, it seems like this is a random string and hence slower to sort. but mongoDB creates this string in natural ascending order of creation. That is, documents created later will always show up later in asending sort naturally. As this field is also indexed, mongoDB does not need to do any sorting during query time – it simply returns the indexed document collection.
When you use the MongoDB sort() method, you can specify the sort order—ascending (1) or descending (-1)—for the result set. If you do not index for the sort field, MongoDB will sort the results at query time. Sorting at query time uses CPU resources and delays the response to the application. However, when an index includes all fields used to select and sort the result set in proper order, MongoDB does not need to sort at query time. Instead, results are already sorted in the index, and can be returned immediately.
The reason objectID is designed the way it is, is beause it saves you the effort to add another property – timestamp – to track the creation of the document.
One of the main reasons ObjectId’s are generated in the fashion mentioned above by the drivers is that is contains a useful behavior due to the way sorting works. Given that it contains a 4 byte timestamp (resolution of seconds) and an incrementing counter as well as some more unique identifiers such as the machine id once can use the _id field to sort documents in the order of creation just by simply sorting on the _id field. This can be useful to save the space needed by an additional timestamp if you wish to track the time of creation of a document.
Over at this seminar, Jonathan Tower mentions a bad practice of implementing microservice – one in which A acceses the database of microservice B directly!

This made me think: It’s all good in theory to state that this is not a recommended approach but what could be a good reason for the same? Here’s a good answer
If you tie a couple of components to an RDBMS directly, and you see one particular component becoming a performance bottle-neck for which you might want to denormalize the database, but you can’t because all other components would be affected. You may even realize that you’d be better off with a document store or a graph database than with an RDBMS. If the data is encapsulated by a small API, you have a realistic chance to reimplement said API any way you need. You can transparently insert cache layers and what not.
Fumbling with the storage layer directly from the application layer is the diametrical opposite of what the dependency inversion principle suggests to do.
Another good answer
What is more important and significant about a microservice: its API or its database schema? The API, because that is its contract with the rest of the world. The database schema is simply a convenient way of storing the data managed by the service, hopefully organised in a way that optimises the microservice´s performance. The development team should be free to reorganise that schema – or switch to an entirely different datastore solution – at any time. The rest of the world should not care. The rest of the world cares when the API changes, because the API is the contract.
The reason I write this is because I have experienced this in a recent project. Third parties wanted access our data without coming to our product site. But we didn’t want our server to have additional requests from third parties, so we created an “integration” app that will receive those requests (in order to protect our server from additional hits from rogue areas). That wouldn’t stop the additional burden on our main database, would it? So we decided to make a read replica. The main database continues to be tied only to our product webapp and read replica for third party access. The idea would be to directly write queries on the read replica from the new microservice. The issue is that whenever there is re-organization of our main database – and in turn the read replica – it would mean re-writing the queries on the integration microservice. No reorganization can be done in an isolated maneer. The reorganization leaks to all other services that are directly tied to it. In general, even our implementation is not a microservice, it is a distributed monolith