
Little useless-useful R functions – Typing speed benchmark
[This article was first published on R – TomazTsql, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Did you ever wonder how fast and with accuracy your typing is?
For this instance, we will introduce some random pangrams, code samples and random strings sotrted by level of difficulty.
# list of phrases is generated with the help of LLM. Because ..lazy!!!!phrases_db <- list( pangram = list( easy = c( "The quick brown fox jumps over the lazy dog", "Pack my box with five dozen liquor jugs", "How vexingly quick daft zebras jump", "The five boxing wizards jump quickly", "Sphinx of black quartz judge my vow" ), medium = c( "The quick brown fox jumps over the lazy dog while the cat watches", "A wizard's job is to vex chumps quickly in fog with zebra tricks", "Crazy Frederick bought many very exquisite opal jewels last week", "We promptly judged antique ivory buckles for the next prize winner", "Six big devils from Japan quickly forgot how to waltz in my room" ), hard = c( "The job requires extra pluck and zeal from every young wage earner, quickly!", "Grumpy wizards make a toxic brew for the jovial queen who lives in a palace", "Back in June we delivered oxygen equipment of the same size to a new complex", "A quivering Texas zombie fought republic linked jewelry and quartz watches", "The explorer was frozen in his survey before he made a quartz and jade box" ) ), pangram_slo = list( easy = c( "Škrbast mož fizično dviguje hlapca", "Iščem vzdolžen grb ptujskih fac", "Črn šef Gambijk hupa vzdolž cest" ), medium =c( "Ščepec soli fajn zažge tobak v sodih ruma", "Cagav bledoličnež nima škafa za prst juhe", "Vzdržljivi fant mečka gobec hišnemu psu" ), hard = c( "Škodoželjno ga je zafrknil - ni mu pustil več hlebca", "Majceni krastači vrh polža se gabi študij fizike", "Prgišče klofute včasih bolj zaleže od močne brce", "Pretkani gofljač razmišlja o zgodbicah sužnjev", "Fantu, ki je zbrcal špičasto mevžo, hudo grozijo" ) ), rstats = list( easy = c( "The mean is sensitive to outliers", "Always visualize your data first", "Check for missing values early", "The sample size was too small", "R is a language for statistics" ), medium = c( "The p-value was significant at alpha 0.05", "Always check your residuals for normality", "Correlation does not imply causation", "The model explains 87 percent of variance", "Use cross-validation to prevent overfitting", "The confidence interval contains the true mean", "Random forests reduce variance through bagging" ), hard = c( "The heteroscedasticity in residuals violates OLS assumptions", "Apply Bonferroni correction for multiple hypothesis testing", "The likelihood ratio test compares nested model specifications", "Multicollinearity inflates standard errors of coefficients", "Use bootstrapping when parametric assumptions are violated" ) ), code = list( easy = c( "x <- c(1, 2, 3, 4, 5)", "mean(x, na.rm = TRUE)", "print('Hello, World!')", "df <- data.frame(a = 1:5)", "sum(is.na(data))" ), medium = c( "df <- data.frame(x = 1:10, y = rnorm(10))", "result <- sapply(my_list, mean, na.rm = TRUE)", "filtered <- subset(df, value > 0 & group == 'A')", "model <- lm(y ~ x + z, data = train_set)", "apply(matrix_data, MARGIN = 2, FUN = sd)" ), hard = c( "result <- lapply(my_list, function(x) mean(x, na.rm = TRUE))", "ggplot(data, aes(x, y)) + geom_point() + theme_minimal()", "df %>% group_by(category) %>% summarise(avg = mean(value))", "tryCatch(expr = risky_function(), error = function(e) NULL)", "Map(function(x, y) x^2 + y, list_a, list_b)" ) ), chaos = list( easy = c( "df$column[1:5]", "list[[1]]$value", "x <- y + z * 2", "a & b | !c", "func(x = 1, y = 2)" ), medium = c( "data[[1]]$results[[2]]$value", "df[df$x > 0 & !is.na(df$y), ]", "paste0('value_', 1:5, collapse = ', ')", "grepl('^[A-Z]{2,3}$', strings)", "sprintf('%s: %.2f%%', name, pct * 100)" ), hard = c( "purrr::map2_dfr(.x = list_a, .y = list_b, .f = ~.x + .y)", "regex <- '\\\\d{4}-\\\\d{2}-\\\\d{2}\\\\s\\\\d{2}:\\\\d{2}'", "eval(parse(text = paste0('func_', i, '(x = ', j, ')')))", "do.call(rbind, lapply(1:n, function(i) df[sample(nrow(df), 1), ]))", "Reduce(function(acc, x) c(acc, x^2), 1:10, init = numeric(0))" ) ))
Addition to list of sample strings, we have also couple of helper functions – calculating WPM, accuracy and handling inputs and results for user:
calculate_wpm <- function(text, time_seconds) {
char_count <- nchar(text)
word_count <- char_count / 5
time_minutes <- time_seconds / 60
wpm <- word_count / time_minutes
return(round(wpm, 1))
}
calculate_accuracy <- function(original, typed) {
orig_chars <- strsplit(original, "")[[1]]
typed_chars <- strsplit(typed, "")[[1]]
orig_len <- length(orig_chars)
typed_len <- length(typed_chars)
if (typed_len == 0) {
return(0)
}
compare_len <- min(orig_len, typed_len)
matches <- sum(orig_chars[1:compare_len] == typed_chars[1:compare_len])
length_penalty <- abs(orig_len - typed_len)
accuracy <- (matches / orig_len) * 100
penalty_pct <- (length_penalty / orig_len) * 100
accuracy <- max(0, accuracy - penalty_pct)
return(round(accuracy, 1))
}
get_random_phrase <- function(mode = "pangram", difficulty = "medium") {
valid_modes <- c("pangram", "rstats", "code", "chaos")
if (!mode %in% valid_modes) {
warning(paste("Invalid mode; use one of these modes:",
paste(valid_modes, collapse = ", ")))
mode <- "pangram"
}
valid_difficulties <- c("easy", "medium", "hard")
if (!difficulty %in% valid_difficulties) {
warning(paste("Invalid difficulty; use one of these difficulties:",
paste(valid_difficulties, collapse = ", ")))
difficulty <- "medium"
}
phrase_pool <- phrases_db[[mode]][[difficulty]]
phrase <- sample(phrase_pool, 1)
return(phrase)
}
##### Diplay results
display_results <- function(wpm, accuracy, time_seconds) {
cat("\n")
cat(rep("\U00002550", 48), "\n", sep = "")
cat(" RESULTS\n")
cat(rep("\U00002550", 48), "\n", sep = "")
cat("\n")
cat(sprintf(" Time: %.2f seconds\n", time_seconds))
cat(sprintf(" WPM: %.1f \n", wpm))
cat(sprintf(" Accuracy: %.1f%% \n", accuracy))
cat("\n")
cat(rep("\U00002550", 48), "\n", sep = "")
}
show_error_details <- function(original, typed) {
orig_chars <- strsplit(original, "")[[1]]
typed_chars <- strsplit(typed, "")[[1]]
max_len <- max(length(orig_chars), length(typed_chars))
if (length(orig_chars) < max_len) {
orig_chars <- c(orig_chars, rep("_", max_len - length(orig_chars)))
}
if (length(typed_chars) < max_len) {
typed_chars <- c(typed_chars, rep("_", max_len - length(typed_chars)))
}
errors <- which(orig_chars != typed_chars)
if (length(errors) == 0) {
cat("\n Perfetoooo! \n")
return(invisible(NULL))
}
cat("\n Errors:\n")
cat(" --------------\n")
show_errors <- head(errors, 5)
for (pos in show_errors) {
expected <- if (orig_chars[pos] == " ") "[space]" else orig_chars[pos]
got <- if (typed_chars[pos] == " ") "[space]" else
if (typed_chars[pos] == "_") "[missing]" else typed_chars[pos]
cat(sprintf(" Position %d: expected '%s', got '%s'\n", pos, expected, got))
}
if (length(errors) > 5) {
cat(sprintf(" ... and %d more errors\n", length(errors) - 5))
}
}
### Function itself
TypingTest <- function(mode = "code",
difficulty = "easy",
show_errors = TRUE) {
# Display header
cat("\n")
cat("\U00002554", rep("\U00002550", 52), "\U00002557\n", sep = "")
cat("\U00002551 R TYPING SPEED TEST \U00002551\n")
cat("\U00002551 Mode: ", sprintf("%-10s", mode), " | Difficulty: ",
sprintf("%-8s", difficulty), "\U00002551\n", sep = "")
cat("\U0000255A", rep("\U00002550", 52), "\U0000255D\n", sep = "")
cat("\n")
phrase <- get_random_phrase(mode, difficulty)
cat("Type the following:\n\n")
cat(" \"", phrase, "\"\n\n", sep = "")
cat("Press ENTER when ready to start...")
invisible(readline())
cat("\n----------------------------------------------------------\n")
cat(" \"", phrase, "\"\n", sep = "")
cat("----------------------------------------------------------\n\n")
start_time <- Sys.time()
typed <- readline(prompt = "> ")
end_time <- Sys.time()
time_seconds <- as.numeric(difftime(end_time, start_time, units = "secs"))
wpm <- calculate_wpm(phrase, time_seconds)
accuracy <- calculate_accuracy(phrase, typed)
display_results(
wpm = wpm,
accuracy = accuracy,
time_seconds = time_seconds
)
if (show_errors && accuracy < 100) {
show_error_details(phrase, typed)
}
cat("\nPlay again? (y/n): ")
play_again <- tolower(readline())
if (play_again == "y" || play_again == "yes") {
return(TypingTest(mode = mode, difficulty = difficulty, show_errors = show_errors))
}
}
At the end, all we need to do is to run the function itself:
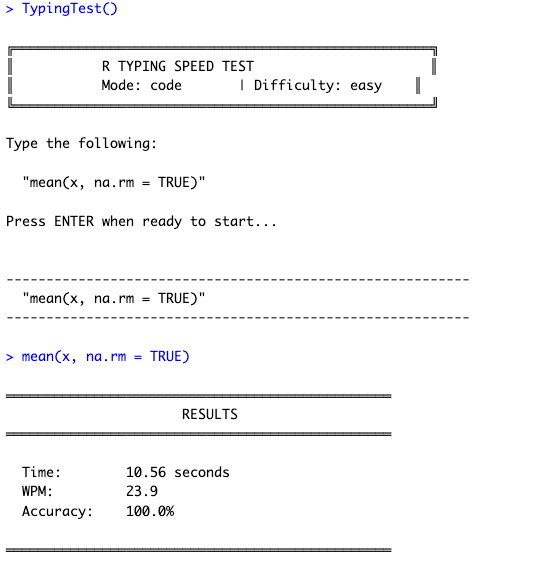
######### Run the function!######TypingTest()
Results are displayed:
As always, the complete code is available on GitHub in Useless_R_function repository. The sample file in this repository is here (filename: TypingSpeed_tester.R.R). Check the repository for future updates.
Happy R-coding and stay healthy!
To leave a comment for the author, please follow the link and comment on their blog: R – TomazTsql.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.