 During a recent working session, some Oceanerc (incl. me) went reading Privacy-Preserving Parametric Inference: A Case for Robust Statistics by Marco Avella-Medina (JASA, 2022), where robust criteria are advanced as efficient statistical tools in private settings. In this paper, robustness means using M-estimators T—as function of the empirical cdf—with basis score functions Ψ, defined as
During a recent working session, some Oceanerc (incl. me) went reading Privacy-Preserving Parametric Inference: A Case for Robust Statistics by Marco Avella-Medina (JASA, 2022), where robust criteria are advanced as efficient statistical tools in private settings. In this paper, robustness means using M-estimators T—as function of the empirical cdf—with basis score functions Ψ, defined as

where Ψ is bounded. A construction further requiring that one can assess the sensitivity (in Dwork et al, 2006, sense) of a queried function, sensitivity itself linked with a measure of differential privacy. Because standard robustness approaches à la Huber allow for a portion of the sample to issue from an outlying (arbitrary) distribution, as in ε-contaminations, it makes perfect sense that robustness emerges within the differential framework. However, this common sense perception does not seem good enough for achieving differential privacy and the paper introduces a further randomization with noise scaled by (n,ε,δ) in the following way

that also applies to test statistics. This scaling seems to constitute the central result of the paper, which establishes asymptotically validity in the sense of statistical consistency (with the sample size n). But I am left wondering whether this outcome counts as supporting differential privacy as a sensible notion…
“…our proofs for the convergence of noisy gradient descent and noisy Newton’s method rely on showing that with high probability, the noise introduced to the gradients and Hessians has a negligible effect on the convergence of the iterates (up to the order of the statistical error of the non-noisy versions of the algorithms).” Avella-Medina, Bradshaw, & Loh
As a sequel I then read a more recent publication of Avella-Medina, Differentially private inference via noisy optimization, written with Casey Bradshaw & Po-Ling Loh, which appeared in the Annals of Statistics (2023). Again considering privatised estimation and inference for M-estimators, obtained by using noisy optimization procedures (noisy gradient descent, noisy Newton’s method) and constructing noisy confidence regions, that output differentially private avatars of standard M-estimators. Here the noisification goes through a randomisation of the gradient step like

where B is an upper bound on the gradient Ψ, η is a discretization step, and K is the total number of iterations (thus fixed in advance). The above stochastic gradient sequence converges with high probability to the actual M-estimator in n and not in K, since the upper bound on the distance scales in √K/n. Where does the attached privacy guarantee come from? It proceeds by an argument of a composition of a sequence of differentially private outputs, all based on the same dataset.
“…the larger the number [K] of data (gradient) queries of the algorithm, the more prone it will be to privacy leakage.”
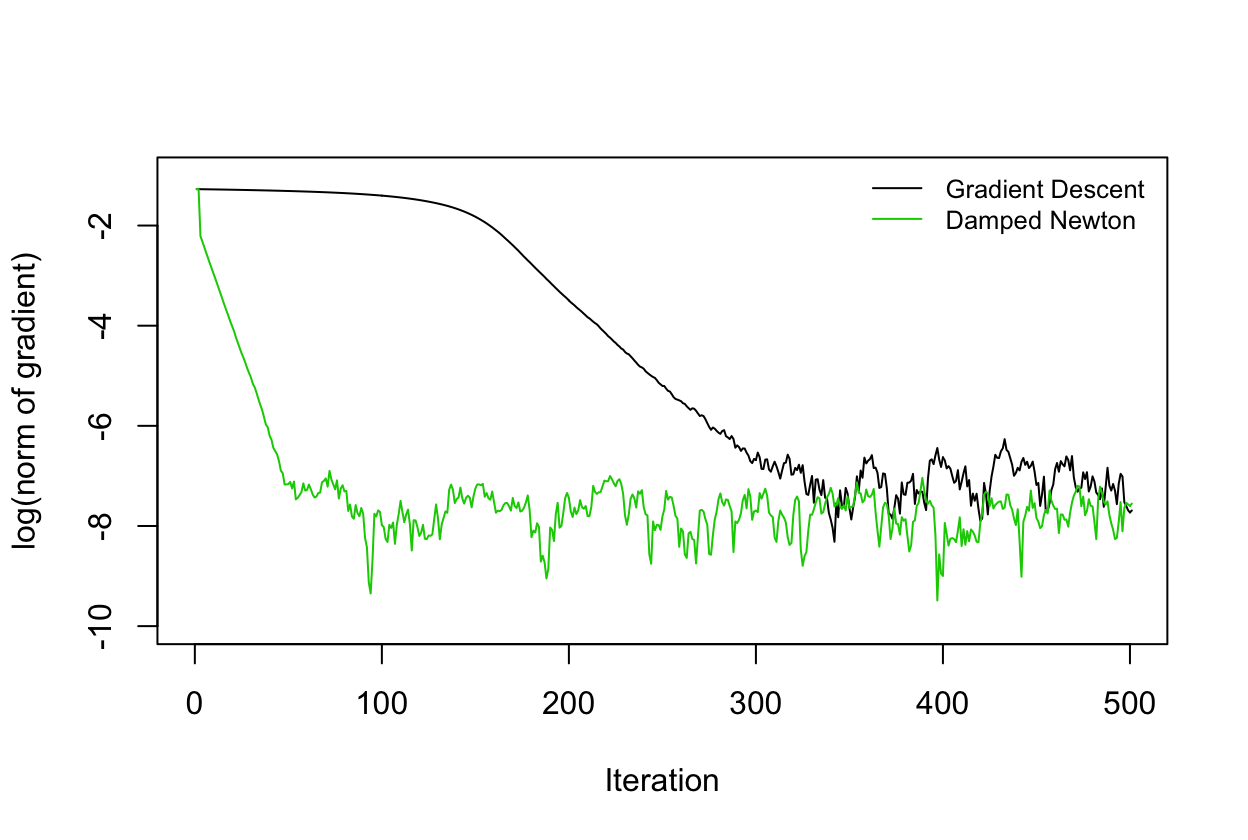
The Newton method version is a variation on the above stochastic gradient descent. Except it seems to converge faster, as illustrated above.





